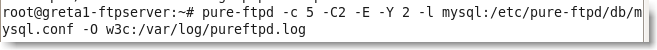
Figure 1.
|
La compagnie nationale de télécommunication américaine (AT&T) développe en 1969 dans son laboratoire Bell Labs un système d'exploitation nommé Multics pour la gestion de son système d'information.Le but de ce système, commencé en 1964, était:
pouvoir être utilisé par plusieurs personnes à la fois.
pouvoir exécuter des calculs en tâche de fond.
La gestion des fichiers, quelques commandes simples et pour finir un interpréteur de commandes (le shell) sont alors mis au point. Le nom d'Unix est choisi.
Entre 1971 et 1973 Unix est réécrit en langage C , à l'époque tout nouveau, assurant ainsi la portabilité du système sur d'autres architectures (machines).
Le système est alors redistribué auprés des centres de recherches et grandes universités qui le font évoluer en suivant deux principales branches:
BSD (Berkeley Software Distribution)
Unix System V qui a donné des systèmes comme Sun Solaris ou HP-UX
Certains Unix sont gratuits (OpenBSD, FreeBSD,...) et d'autres payants (AIX, Tru64).
En 1990, un jeune étudiant finlandais, Linus Torvalds développe un noyau à partir d'un Unix adapté aux processeurs Intel x86 (nommé Minix). La première version est présentée en septembre 1991. Il utilise alors bash et gcc et l'architecture de fichiers Unix .
La première Distribution commerciale, Slackware, sort en 1993, la version 1 du noyau Linux en 1994. Rapidement d'autre distributions apparaissent: Debian , Red Hat, ...
Une distribution est composée du noyau Linux, d'un système de fichiers, d'un programme d'installation, d'un gestionnaire de paquets, et d'un ensemble d'utilitaires ... Le noyau est le coeur du système d'exploitation, complété par un sytème de fichiers et des outils pour pouvoir l'utiliser.
Actuellement le noyau en est à sa version 2.6.
Open Source signifie que le logiciel est livré avec son code source (écriture en langage de programmation avant compilation)afin de permettre la compréhension et la modification éventuelle du programme.
Richard Stallman (chercheur) a posé les bases de la philosophie du Logiciel libre:
0. Liberté d'exécution du logiciel
Liberté d'accés au code source
Liberté de redistribution
Liberté d'amélioration
Ce sont les « quatres libertés ».
Il crée la licence GPL qui est le cadre juridique du logiciel libre: Personne ne peut s'approprier un code GPL. Il fonde alors le projet GNU (acronyme récursif de GNU is not Unix...) qui après l'adhésion de Linus Torvalds à la licence GPL devient GNU/Linux.Il existe maintenant différents types de licences.
2LES PRINCIPALES
DISTRIBUTIONS
Red Hat :inventeur du système de gestion de paquets RPM, utilisé par Mandriva ou SuSE . Séparé maintenant en deux parties: Fedora (gratuite) et Red Hat Enterprise Linux (payante) destinée aux entreprises.
Mandriva (anciennement Mandrake) dont le but est la simplicité d'installation et d'utilisation (avec également une gamme corporate ).
Debian a pour seul support la communauté Open Source, mais qui est une des mieux structurée, en particulier au niveau de la gestion des dépendance des paquetages.
Ubuntu , distribution non commerciale basée sur Debian et lancée en 2004 par Mark Shuttleworth et sponsorisée par sa société Canonical Ltd . Conçue pour les ordinateurs de bureau avec pour objectif la convivialité et l'ergonomie.
Gentoo est réservée aux spécialistes et aux passionnés car elle est basée sur la recompilation totale du système sur la machine à laquelle elle est destinée(meilleure optimisation, mais nécessite beaucoup de temps et peut entrainer des complications).
En pratique: nous allons utiliser la dernière distribution Ubuntu disponible à ce jour Intrepid Ibex 8.10 . Votre machine doit donc être bootable à partir du cdrom d'installation
Suivre ensuite la procédure ci-dessous:
|
Figure 1.
|
 |
Figure 2.
|
 |
Figure 3.
|
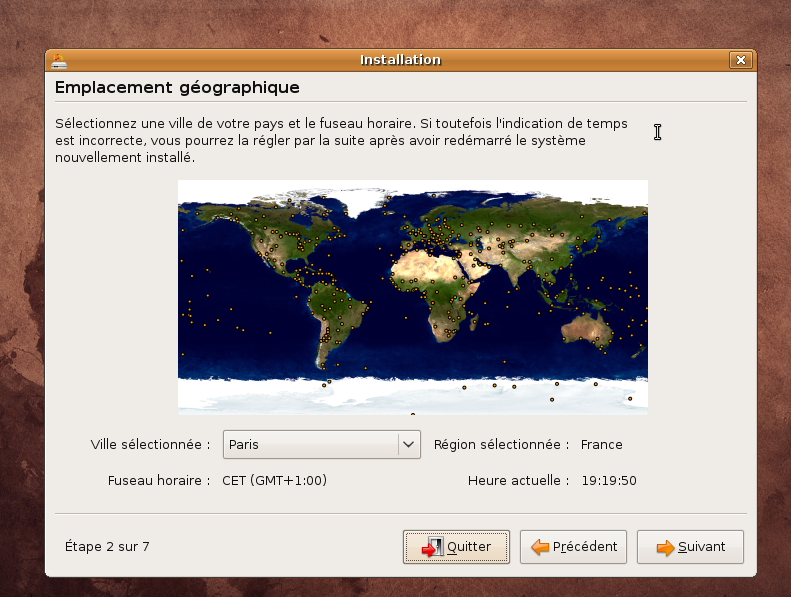 |
Figure 4.
|
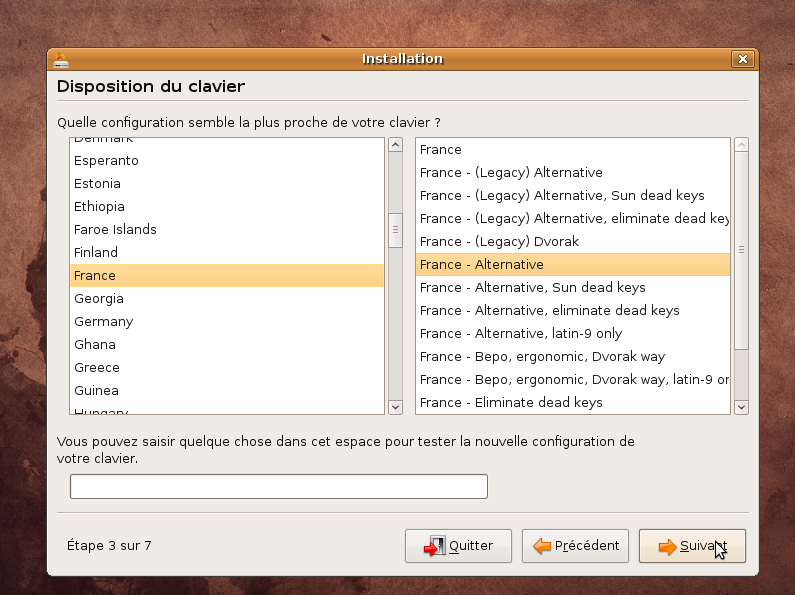 |
Figure 5.
|
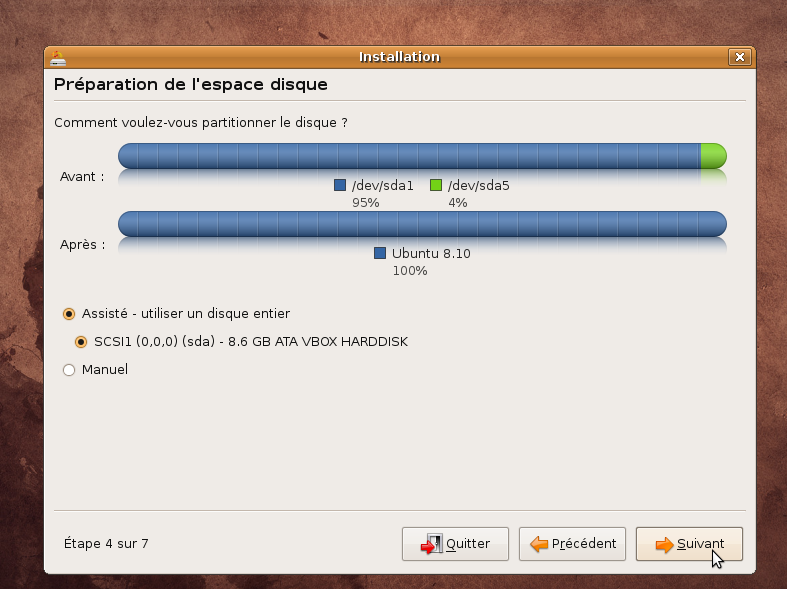 |
Figure 6.
|
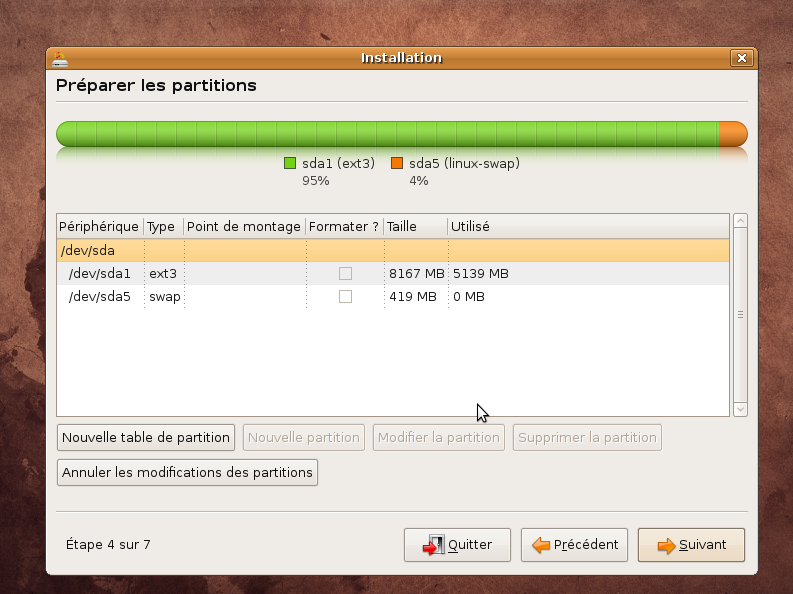 |
Figure 7.
|
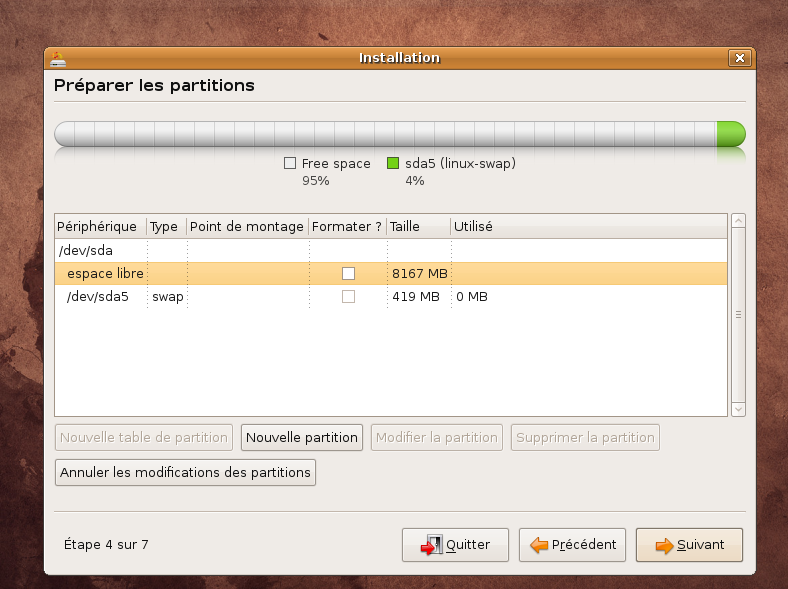 |
Figure 8.
|
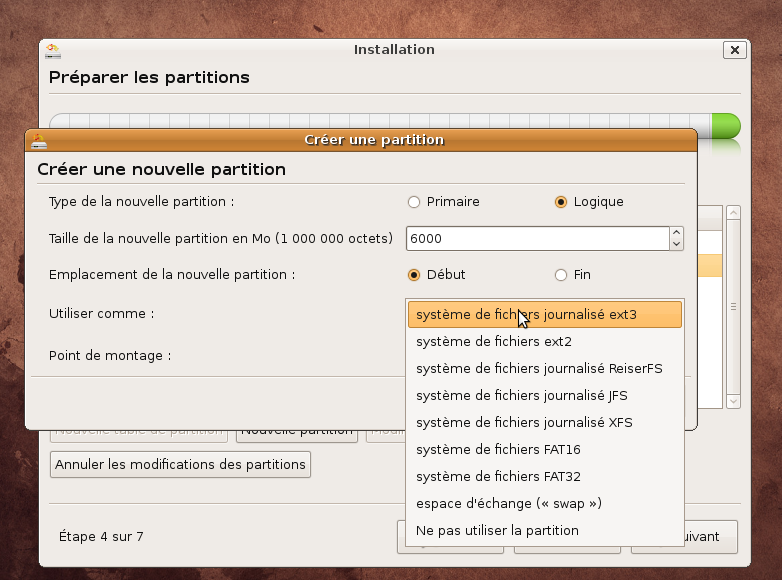 |
Figure 9.
|
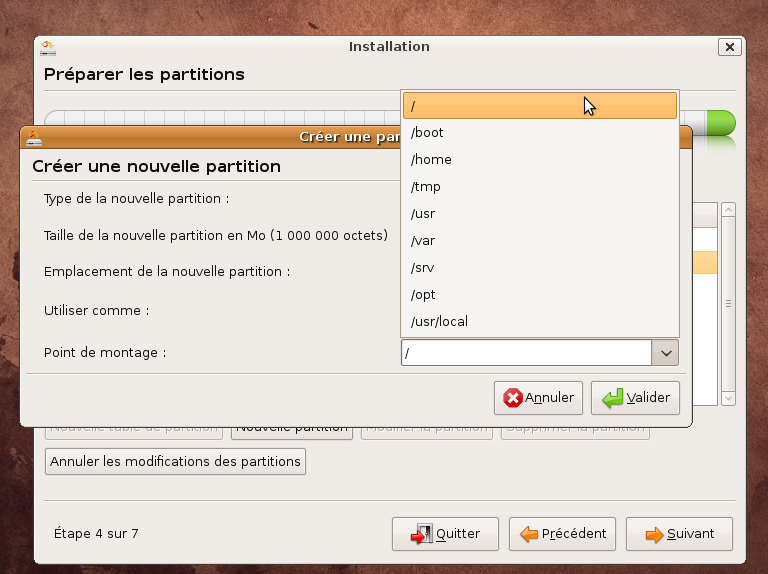 |
Figure 10.
|
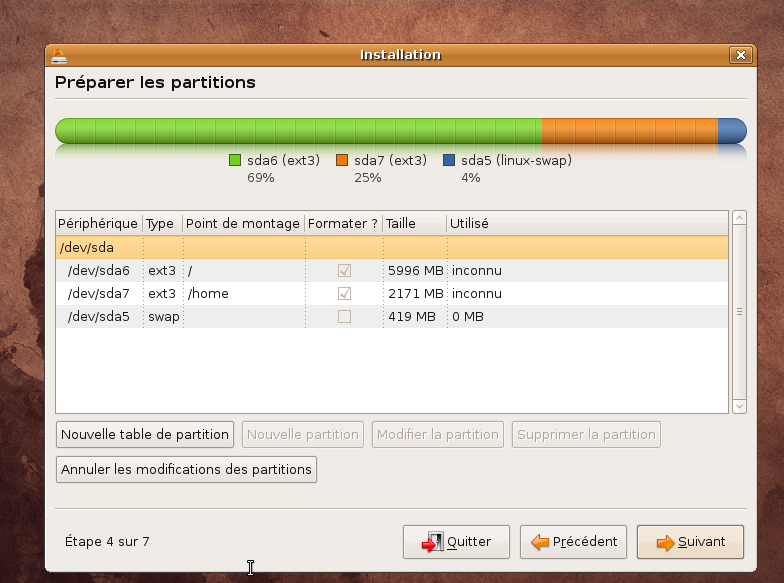 |
Figure 11.
|
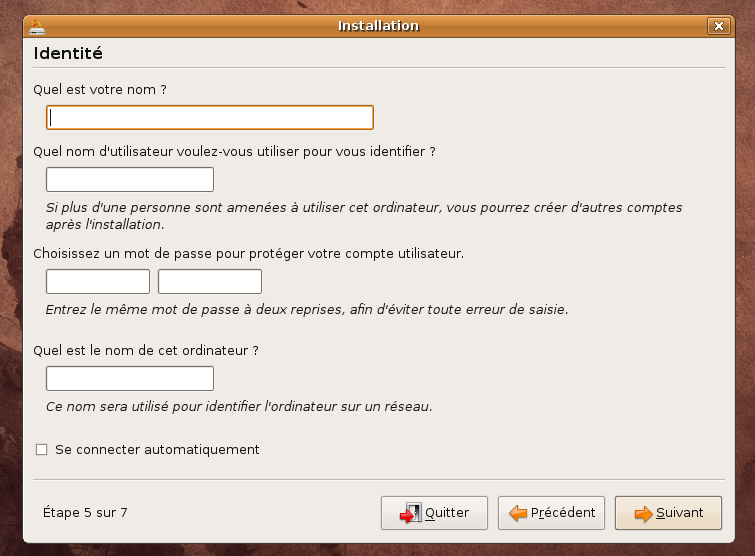 |
Figure 12.
|
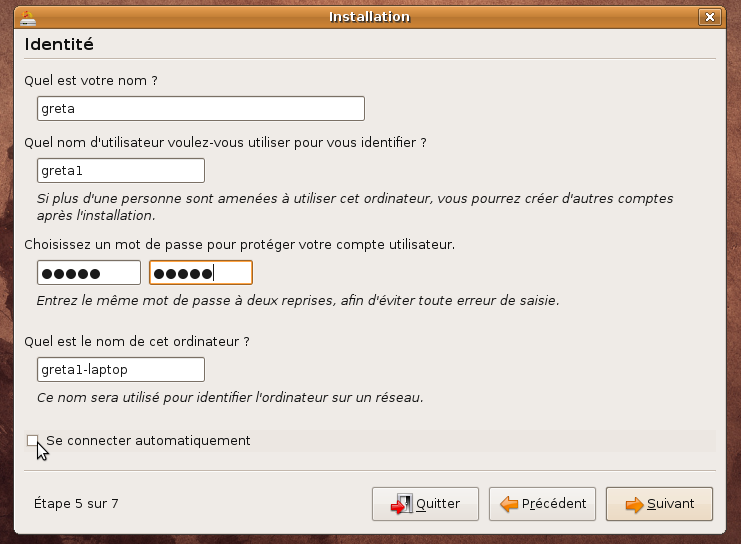 |
Figure 13.
|
A l'écran de connexion, demandez un terminal .
REMARQUE: il est possible de se connecter à plusieurs terminaux en même temps grâce à la combinaison des touches Ctrl + Alt et Fn (ex.: Ctrl+Alt+F1)
login: greta1
password: greta
On utilise la ligne de commande, ou CLI (Command Line Interface).
Il existe deux types de comptes:
utilisateurs (users) dont l'invite de commande est du type : user@localhost$ (ici greta1@greta-laptop$)
root qui est le compte administrateur système ou superutilisateur qui a tous les droits . Son invite de commande est : root@localhost# (ici root@greta-laptop).
Remarques:
Sous Ubuntu, par sécurité, le compte root est désactivé par défaut, mais on peut utiliser la commande sudo pour effectuer les tâches d'administration. Toutefois, pour nos besoins “pédagogiques”, nous allons activer ce compte.
tapez : sudo -s puis passwd
Le mot root (racine en français) désigne deux choses sous linux:
le compte administrateur, mais aussi,
la racine du système de fichiers (comme on va le voir ci-dessous).
Le système de fichiers commun à Unix et Linux suit une convention. Grâce à cette convention, lors de l'installation ou l'utilisation de programmes, les fichiers s'écrivent dans les “bons” répertoires. Avec le F.H.S., tout est fichier(une imprimante est un fichier dans lequel on va écrire).
La base de l'arborescence (la racine) est le slash “/” ou root. Le dossier racine contient les dossiers élémentaires suivants:
| Remarque: on obtient le contenu d'un dossier en tapant la commande : ls “nom du dossier”. |
par exemple, ici : greta1@greta-laptop$ ls /
| dossier | contenu |
| /bin | les fichiers executables vitaux (binaires) |
| /boot | les fichiers du boot(démarrage) et sa configuration |
| /dev | tous les périphériques |
| /etc | tous les fichiers de configuration et les scripts nécessaires au démarrage |
| /home | les répertoires personnels des utilisateurs (users) |
| /lib | les librairies partagées et noyaux du système |
| /mnt | les points de montage temporaires (voir dossier /media) |
| /proc | accés direct aux paramètres du noyau |
| /root | le répertoire personnel du superutilisateur (administrateur ou root) |
| /sbin | les fichiers executables vitaux pour le superutilisateur |
| /tmp | les dossiers et fichiers temporaires (vidé à chaque démarrage) |
| /usr | unix system resources tout ce qui n'est pas vital au système |
| /var | tout ce qui change fréquemment (logs, emails, queues d'impressions) |
Cette architecture se reproduit en partie à l'intérieur du dossier /usr.
Tapez: greta1@greta-laptop$ ls /usr
|
Tapez: greta1@greta-laptop$ ls /var
| /var/log | tous les fichiers de log |
| /var/mail | tous les fichiers mails |
| /var/run | tous les fichiers PID(1) des daemons(2) |
(1) Process IDentifier (2)daemons: Disk And Extensions MONitor.(programmes en tâche de fond attendant un évènement le concernant.
| Perdus ?: pour savoir où vous êtes, tapez la commande “pwd” |
exemple: greta1@greta-laptop$ pwd
/home/greta1
Pour se déplacer dans l'arborescence, il existe deux types de chemins:
le chemin absolu : on part toujours de la racine. (ex.: /usr/local/bin ; /home/greta1 ; /var/log ...)
exercice: tapez successivement les commandes ls “chemin absolu” où vous remplacez “chemin absolu” par les expressions précédentes.
Vous obtenez le contenu de ces répertoires, mais vous n'avez pas bougé. Vous êtes toujours dans le répertoire initial (/home/greta1).
Pour se déplacer , on utilise la commande cd (change directory). Par exemple, tapez: cd /var/log puis pwd et enfin ls . A titre d'exercice, retournez dans votre répertoire personnel.
le chemin relatif : on part du répertoire dans lequel on se trouve. On utilise alors les préfixes suivants: “..” pour remonter d'un niveau et “.” pour indiquer le niveau actuel.
exercice: Placer vous dans votre répertoire utilisateur puis tapez la commande suivante: greta1@greta-laptop$ cd ../../usr/local puis : greta1@greta-laptop$ pwd .
Le shell assure éxecute les commandes entrées dans le terminal par l'utilisateur. Il existe plusieurs shell avec des spécificités différentes:
bash (sous OS X ou Mandriva)
csh (sur les systèmes BSD)
sh (le shell original développé par Steve Bourne)
Nous utilisons donc le bash.
Remarque: à tout moment, le manuel d'une commande peut être obtenu en appelant: man nom-de-la-commande. Par exemple:
 |
Figure 14.
|
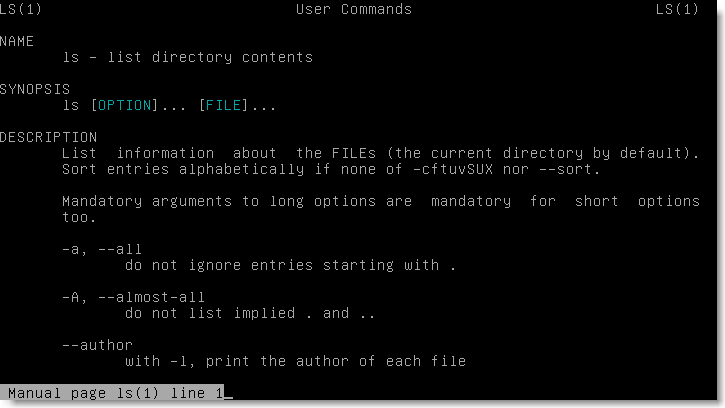 |
Figure 15.
|
Une recherche de mots peut également être réalisée:
 |
Figure 16.
|
|
||||||||||||||||||
Table 1.
|
Exemples d”utilisations et découverte de quelques options essentielles (exercices ):
créer un répertoire nommé sauvegarde dans le répertoire personnel de l'utilisateur greta1.
copier le répertoire /boot et son contenu dans sauvegarde(on utilisera l'option -R pour récursif).
créer un lien sur le Bureau vers le répertoire sauvegarde(on utilisera l'option -s pour symbolique).
créer un lien sur le Bureau vers le répertoire Documents de l'utisateur greta1(on utilisera l'option -s pour symbolique).
visualiser le contenu du dossier boot creé à la question b).
se déplacer dans le répertoire Documents de l'utisateur greta1.
en utilisant la commande touch créer un fichier nommé essai.txt .
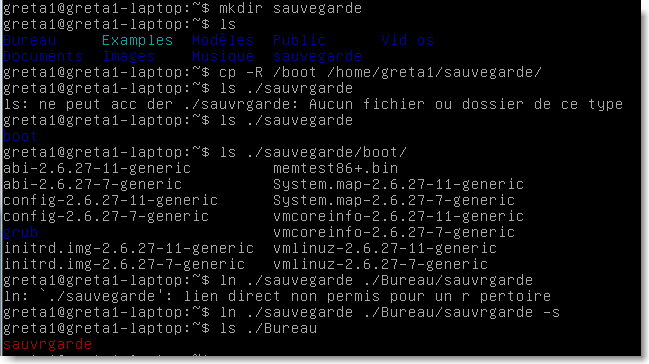 |
Figure 17.
|
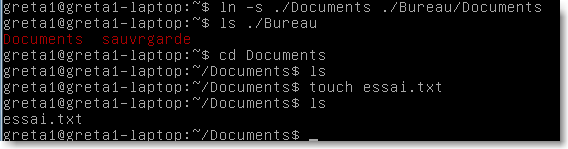 |
Figure 18.
|
Sous Linux, il faut tenir compte des majuscules et des minuscules (on dit que le système est sensible à la casse). Le nom d'un fichier peut contenir jusqu'à 255 caractères alphanumériques. Il est donc possible d'utiliser les caractères spéciaux (espaces,.,_,-, etc...). Toutefois, pour accéder à un fichier dont le nom comporte des caractères spéciaux, on doit utiliser les guillemets autour du nom ou des antislashs avant les caractères spéciaux. Par exemple:
 |
Figure 19.
|
ou encore:
 |
Figure 20.
|
D'autre part, un ensemble d'attributs est ajouté au fichier afin de préciser le type de fichier ainsi que les pemissions associées.On observe ces attributs en ajoutant l'option -l à la commande ls . Par exemple:
 |
Figure 21.
|
On lit alors dans l'ordre:
le type de fichier (- fichier ordinaire ; d répertoire ; l lien symbolique)
les droits de l'utilisateur
les droits du groupe de l'utilisateur
les droits des autres utilisateurs
le nom de l'utilisateur
le nom du groupe
la taille
la date du dernier accés
le nom
autre exemple:
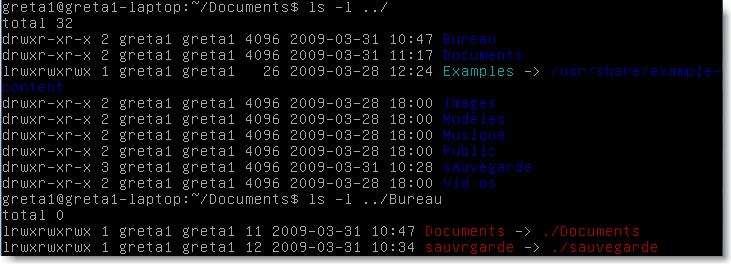 |
Figure 22.
|
| Commande | Description |
| cat fichier | affiche le contenu sur la sortie standart (23) |
| more fichier | affiche le contenu page par page (24 - 25) |
| less fichier | affiche le contenu page par page et permet de remonter dans l'affichage (26) |
| tail -n fichier | affiche les n dernières lignes du fichier |
| head -n fichier | affiche les n premières lignes du fichier |
| grep mot fichier | recherche l'occurence de la chaine de caractère mot dans le fichier |
 |
Figure 23.
|
 |
Figure 24.
|
 |
Figure 25.
|
 |
Figure 26.
|
 |
Figure 27.
|
Un système linux étant entièrement configuré par des fichiers de textes, il existe différents éditeurs (très différents de logiciels tels que word de Microsoft).Nous allons étudier ici deux de ces programmes les plus utilisés pour des raisons différentes: VIM et SED.
Pour démarrer vim, il suffit de taper vim ou même vi en ligne de commande. Sans nom de fichier, on obtient l'écran d'accueil:
 |
Figure 28.
|
Si on précise le nom du fichier on ouvre le fichier correspondant qu'il existe ou non (dans ce cas, il sera créé). Il y a alors trois modes de fonctionnement:
le mode commande obtenu en tapant “:” ou “esc + :”
| Commande | Description |
| :w | enregistre le fichier |
| :w! | force l'enregistrement |
| :w fichier2 | enregistre le fichier sous le nom fichier2 |
| :q | quitte le document |
| :q! | force à quitter (sans enregistrer) |
| :wq | enregistre et quitte |
| V | passe en mode visualisation (pour faire une sélection par exemple) |
| D | couper (après une sélection) |
| Dd | coupe une ligne entière |
| Y | copie (après une sélection) |
| Yy | copie une ligne entière |
| P | colle après le curseur |
le mode insertion (édition des documents) obtenu par les commandes suivantes:
| Commande | Description |
| a | ajoute après le curseur |
| A | ajoute à la fin de la ligne courante |
| i | insère à l'emplacement du curseur |
| I | insère au début de la ligne courante |
| o | ouvre une nouvelle ligne en dessous de la ligne courante |
| O | ouvre une nouvelle ligne au-dessus de la ligne courante |
le mode visuel qui permet de faire des sélections, obtenu à partir du mode commande par la touche V .
 |
Figure 29.
|
sed est un éditeur de texte non interactif, c'est à dire qu'il ne propose pas d'interface de contrôle, mais est capable d'appliquer des séquences de traitement préalablement définies à tout un flux de texte. La syntaxe est la suivante:
 |
Figure 30.
|
où:
-n indique le nombre de lignes à afficher lors de l'envoi d'un texte vers la sortie standard.
-e spécifie la (ou les) commande(s) à effectuer sur le fichier.
-f permet d'indiquer le chemin d'un fichier contenant les commandes sed lorsque celles-ci sont nombreuses (en évite alors la saisie dans -e).
Exemples d'utilisation:
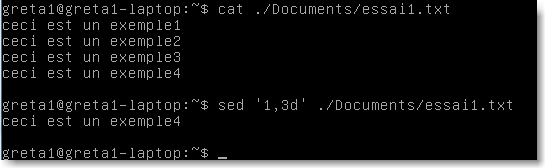 |
Figure 31.
|
ici la commande d supprime les lignes 1 à 3 vers la sortie par défaut (affichage).
 |
Figure 32.
|
ici la commande s substitue le caractère E au caractère e .
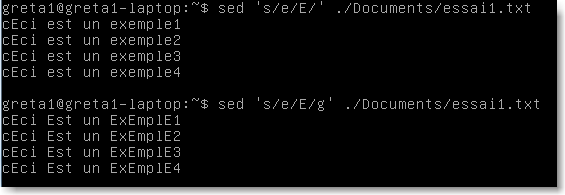 |
Figure 33.
|
le fait d'ajouter l'option g permet de substituer toutes les occurences rencontrées et non pas seulement la première de chaque ligne.
Les autres commandes importantes sont l'insertion \a (insère après la ligne) ou \i (insère avant la ligne), la négation avec le ! qui inverse la commande et l'enregistrement avec le w suivi du nouveau nom de fichier.
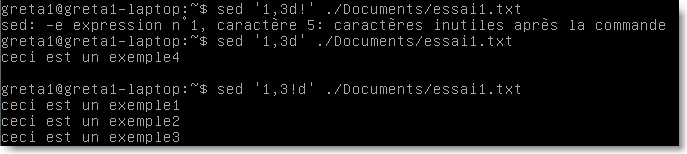 |
Figure 34.
|
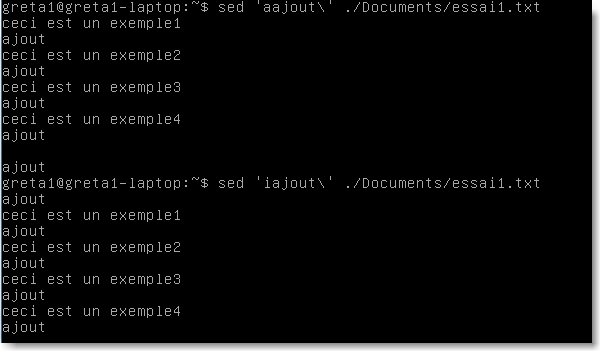 |
Figure 35.
|
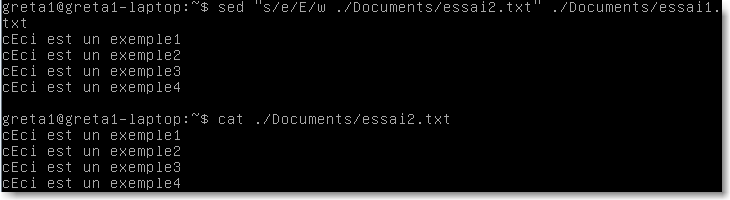 |
Figure 36.
|
Pour plus d'informations sur cet éditeur de texte très puisant pour l'administration de systèmes, voir par exemple:
http://www.minet.net/spip/spip.php?article74
Les deux principaux utilitaires sont tar et gzip .
L'utilitaire tar mémorise l'arborescence des fichiers et des répertoires à archiver(sauf le /de la racine par sécurité). Voici les principales options et quelques exemples nous concernant:
| Option | Description |
| -x | extrait le contenu d'une archive |
| -c | crée une nouvelle archive |
| -t | affiche le contenu de l'archive sans l'extraire |
| -f nom du fichier | indique le nom du fichier archive |
| -v | mode verbeux (commentaires et détails) |
| -z | compresser ou décompresser avec l'utilitaire gzip |
| -j | compresser ou décompresser avec l'utilitaire bzip2 |
| -p | préserver les permissions des fichiers |
 |
Figure 37.
|
 |
Figure 38.
|
On remarque ici l'option -C permettant de préciser le chemin où l'on veut décompresser le fichier.
C'est un utilitaire de compression courant sous linux, comme introduit dans le paragraphe précédent. Il existe également bzip2 qui compresse plus éfficacement les données mais utilise davantage de ressources système.
Les principales options sont:
| Option | Description |
| -1 –> -9 | fixe le niveau de compression (-1 est le moins élevé) |
| -d | décompresse l'archive |
| -c | écrit sur la sortie standard au lieu de remplacer le fichier d'origine |
| -l | affiche les informations sur l'archive |
| -r | parcourt tous les répertoires lors de la décompression (récursivement) |
Exemple:
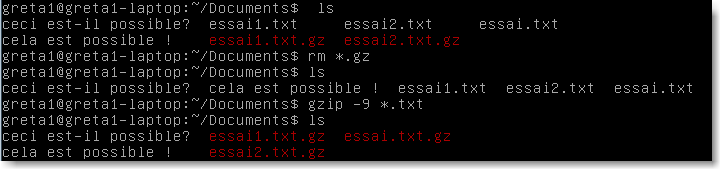 |
Figure 39.
|
Nous terminerons cette introduction au shell par l'étude de la notion de flux d'un programme vers un autre. Il existe trois flux standard:
STDIN (0): canal d'entrée/sortie qui correspond à l'entrée par le clavier ou entrée standard.
STDOUT (1): canal d'entrée/sortie qui correspond à la sortie par l'écran ou sortie standard.
STDERR (2): c'est la sortie d'erreur standard, qui permet de dissocier les messages d'erreurs de l'affichage normal du programme.
La redirection des flux est réalisée par les signes “<” et “>”. Le plus simple est d'observer les exemples suivants:
 |
Figure 40.
|
On a ici un affichage sans redirection.
 |
Figure 41.
|
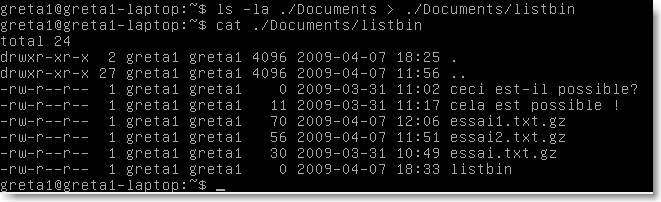
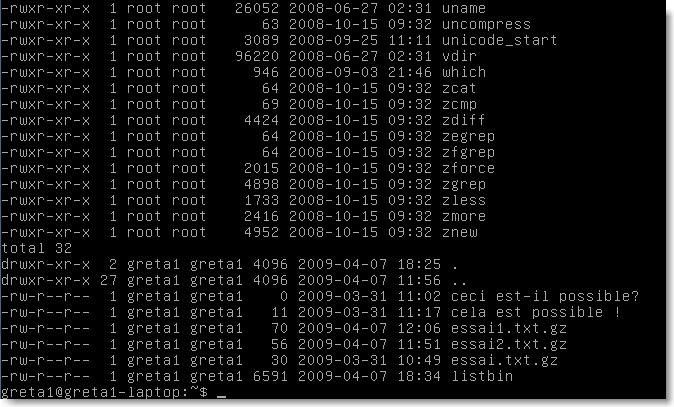
Ici le listage (avec propriétés par l'option -l) du dossier /bin a été écrit dans le fichier listbin. La seconde ligne permet d'afficher le résultat. Si le fichier listbin existait avant, son contenu est écrasé. Pour ajouter des données sans écraser le fichier, on utilise le double symbole “»»>>”:
|
Figure 42.
|
On vient ici d'effectuer des redirection de sortie. Pour les redirections d'entrée, la commande prend en argument le contenu du fichier spécifié. Par exemple, pour rechercher le mot root dans le fichier password, on écrit:
 |
Figure 43.
|
Le deuxième exemple est explicite...
La sortie d'erreur est utilisée de la manière suivante:
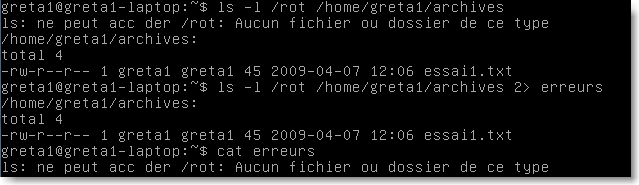 |
Figure 44.
|
Question: pouquoi y avait-il une erreur ?
Pour finir, nous mentionnerons les “|” (pipes) qui sont les voies de communication d'un processus vers un autre. Dans l'instruction command1 | command2 , le résultat de la commande command1 est utilisée en entrée de la commande command2. Par exemple:
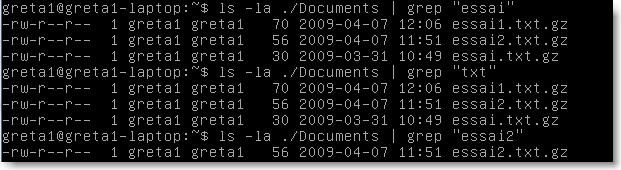 |
Figure 45.
|
Linux est un système multi-utilisateurs et donc l'accés à chaque élément du système (périphérique ou fichier, c'est, pour nous, la même chose) est contrôlé en fonction de l'utilisateur. Un utilisateur n'est pas obligatoirement une personne physique et on utilise alors parfois le terme de pseudo utilisateur. Les règles essentielles de gestion sont les suivantes:
tout utilisateur possède un login (identifiant de connexion)
on associe toujours à ce login un mot de passe personnel
on appelle authentification le processus de connexion par identification/mot de passe
chaque utilisateur est de plus référencé sur le système par un identifiant d'utilisateur, ou UID unique qui est une valeur numérique qui établit une hiérarchie dans les utilisateurs et qui simplifie l'écriture de certaines informations ou permissions.
Le fichier /etc/passwd contient contient toute les informations relatives à tous les utilisateurs du système.
 |
Figure 46.
|
à la fin de ce fichier:
 |
Figure 47.
|
login: identifiant (attention, il ne doit pas comporter de caractères spéciaux)
mot de passe: plusieurs contenus sont possibles.
* :l'authentification sur le système est alors impossible pour ce compte.
!! :le compte est désactivé.
x ou ! :le mot de passe est conservé dans un fichier /etc/shadow en étant crypté par crypt, md5 ou blowfish par la commande passwd.
un champ vide :il n'y a pas de mot de passe défini pour ce compte.
UID :c'est l'identifiant unique de l'utilisateur ( 0 pour le root ; comptes systèmes si UID<100).
GID :c'est l'identifiant du groupe principal de l'utilisateur.
informations utilisateur :elles sont séparées par des virgules (voir l'exemple suivant).
répertoire personnel :c'est l'adresse du répertoire contenant les fichiers appartenant à l'utilisateur (/home/greta1).
shell :c'est l'interpréteur de commande lancé après l'authentification (:/bin/bash).
Remarque: Le fichier /etc/shadow contient les mots de passe cryptés. Seul root peut le lire. Sur certaines distribution l'utilisation de ce fichier peut être ou ne pas être désactivée. La commande pwconv l'active .
Voici un exemple obtenu en ajoutant un utilisateur par la commande adduser:
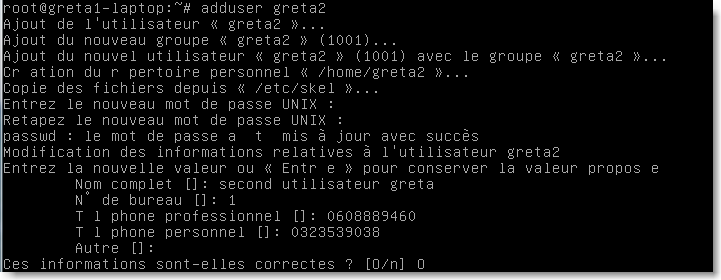 |
Figure 48.
|
 |
Figure 49.
|
La figure 49 donne le résultat obtenu à la fin du fichier /etc/passwd. On remarquera qu'une autre commande permet d'ajouter un utilisateur sans renseigner tous les champs: useradd. Observez:
 |
Figure 50.
|
Les options de cette dernière commande sont:
| Option | Commentaires |
| -c commentaire | précise des infos sur l'utilisateur (nom...) |
| -d répertoire | précise l'adresse du répertoire personnel |
| -e date | précise la date d'expiration du compte (AAAA-MM-JJ) |
| -f nombre de jours | c'est le nombre de jours suivant l'expiration pour désactiver le compte |
| -g groupe principal | nom ou numéro de groupe de l'utilisateur |
| -G groupes supplémentaires | autres groupes auxquels appartient l'utilisateur. |
| -m | crée le répertoire de l'utilisateur |
| -k | copie les fichiers et répertoires du modèle (/etc/skel ) |
| -p | permet de saisir le mot de passe chiffré avec crypt |
| -s | shell lancé à la connexion |
| -u | précise l' UID |
Remarque: si le mot de passe n'est pas défini, le compte est désactivé par défaut.
Un compte peut être supprimer par la commande userdel [-r] login . L'option -r supprime également les répertoires personnels. La commande passwd login permet de changer le mot de passe de l'utilisateur login .
Exercice: changez le mot de passe de greta2 puis supprimez greta4 , greta3 (sans l'option -r) et enfin supprimez greta2 avec l'option -r et vérifiez:
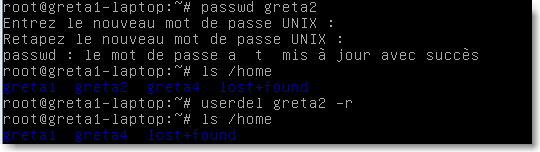 |
Figure 51.
|
Pour afficher les informations des utilisateurs connectés, on peut utiliser une des trois commandes suivantes:
users
who
w
qui donnent des informations plus ou moins détaillées. Et , en cas de doute Shakespearien, vous pouvez essayer:
whoami
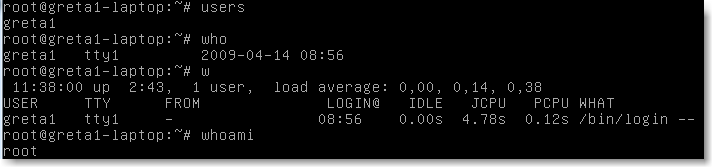 |
Figure 52.
|
Il est possible de changer d'idendité (usurpateurs!) par la commande su (switch user):
su :seul, permet de se connecter en root.
su greta1 :permet d'agir en tant que utilisateur greta1.
su - greta1 :permet d'agir en tant que utilisateur greta1 en récupérant tout l'environnement de l'utilisateur greta1.
su -c commande :permet d'executer une commande en tant que root.
Les groupes permettent de classer les utilisateurs. Les informations d'un groupe du système sont enregistrées dans le fichier /etc/group . Les informations de ce fichiers sont:
group :le nom du groupe.
* :lié aux anciennes versions d'unix, non utilisé, contient * ou x.
GID :identifiant unique du groupe (valeur numérique).
utilisateurs :liste des utilisateurs appartenant au groupe.
Il y a deux types de groupes pour un utilisateur donné:
Principal: c'est le groupe auquel tous les fichiers de l'utilisateur appartiennent par défaut.
Secondaire: utilisé pour gérer plus finement les permissions d'accès au système.
On ajoute un groupe avec la commande groupadd [option] groupe où les options possibles sont :
-g (permet de choisir la valeur du GID); -r (permet d'ajouter un groupe système, GID<500); -f (stoppe la commande si le groupe ou le GID existe déjà).
 |
Figure 53.
|
 |
Figure 54.
|
On peut supprimer un groupe qui n'est pas système ou groupe principal d'un utilisateur existant par la commande: groupdel groupe. On peut également modifier les groupes secondaires d'un utilisateur avec la commande usermod qui supporte les mêmes options que useradd. Par exemple:
 |
Figure 55.
|
ATTENTION: tous les groupes secondaires non précisés dans la commande sont supprimés. Il ne faut donc pas en oublier.
Il sera donc utile de connaître les groupes d'un utilisateur en utilisant la commande groups login .par exemple:
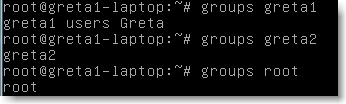 |
Figure 56.
|
La commande id permet de connaitre les groupes actifs. On peut changer de groupe actif par la commande newgrp :
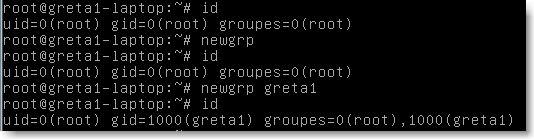 |
Figure 57.
|
Un fichier ”voit” trois types d'utilisateurs différents:
Son propriétaire (qui est souvent son créateur), représenté par la lettre u .
Son groupe (qui comprend tous les utilisateurs appartenant à ce groupe - par défaut celui du propriétaire), représenté par la lettre g .
Tous les autres utilisateurs du système, représenté par la lettre o .
les droits de ces trois types ont étés étudiés lors de l'introduction de la commande ls -l. Par exemple:
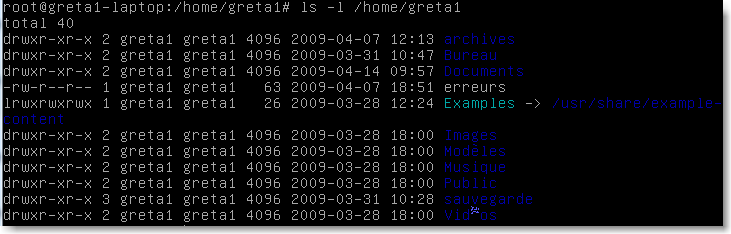 |
Figure 58.
|
On peut changer le propriétaire d'un fichier: par la commande chown
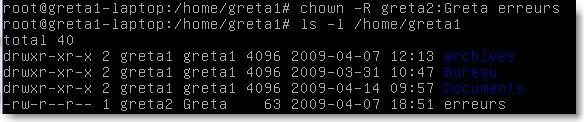 |
Figure 59.
|
L'option -R rend le changement récursif aux sous dossiers s'ils existent, greta2 est le nouveau propriétaire et on a ici changer en même temps de groupe par l'option :Greta , ce qui peut être fait indépendamment par la commande chgrp :
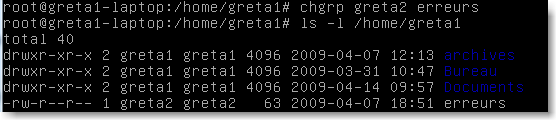 |
Figure 60.
|
Il existe donc pour chaque type d'utilisateur trois types de droits:
Lecture –> r
Ecriture –> w
Execution –> x
Les droits sur les fichiers peuvent êtres modifiés par la commande chmod en utilisant les lettres précédemment définies et les symboles “+”,”-” ou “=” pour ajouter, enlever ou définir des droits. Par exemple:
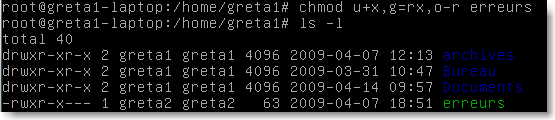 |
Figure 61.
|
On peut également utiliser des valeurs numériques pour compacter l'écriture de la définition des droits. L'équivalence est obtenue en faisant la somme des poids.
| Droit | Lettre | Poids |
| lecture | r | 4 |
| écriture | w | 2 |
| execution | x | 1 |
Ce qui donne par exemple:
 |
Figure 62.
|
ou encore:
 |
Figure 63.
|
Les droits par défaut sont toujours:
666 pour un fichier.
777 pour un répertoire.
On peut toutefois appliquer un filtre de droits pour la création d'un fichier ou d'un répertoire avec la commande umask valeur numérique qui enlève cette valeur numérique aux droits par défaut. Exemple:
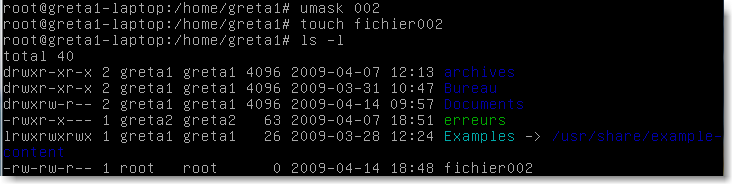 |
Figure 64.
|
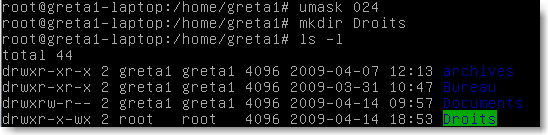 |
Figure 65.
|
Remarque: On rétablit les valeurs par défaut avec umask 000 .
Il existe également des droits spéciaux que nous verrons ultérieurement.
Les disques durs sont repérés comme des fichiers dans l'arborescence. Par convention tous les périphériques sont représentés dans le répertoire /dev par des fichiers suivant la convention:
hd (réf.) pour les disques IDE (par exemple /dev/hda1)
sd (réf.) pour les disques SATA ou SCSI (par exemple /dev/sdd1)
Cette convention est en évolution en foction du matériel comme nous le montre un examen du répertoire /dev d'une intrepid ibex:
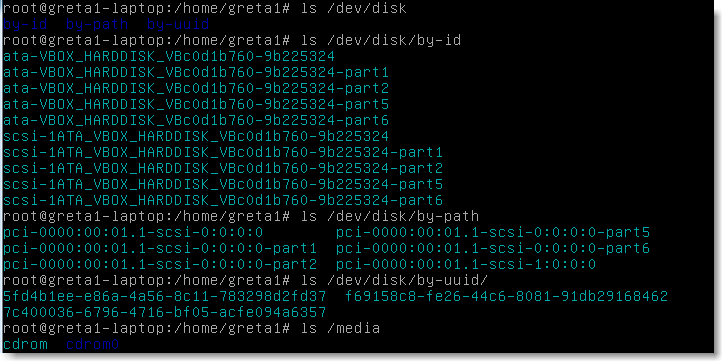 |
Figure 66.
|
Sous linux, un disque peut contenir:
4 partitions primaires
1 de ces partitions peut être définie en tant que partition étendue et contenir alors jusqu'à 12 partitions logiques
Un disque contient donc au maximum 15 partitions utilisables. Chaque partition apparaît deux fois dans le système:
1 fois en tant que périphérique système dans le répertoire /dev
1 fois comme point de montage dans l'arborescence où l'on a une représentation logique de la partition et où les données sont accessibles(le montage va être abordé ci-dessous).
Le partitionnement peut être réalisé en mode graphique (éventuellement à partir d'un livecd) avec gparted, ou en ligne de commande avec fdisk /dev/disque suivi par:
| Commande | Description |
| m | manuel |
| p | affiche l'état |
| n | crée une partition |
| d | supprime une partition |
| t | change le type (82: swap; 83 linux native) |
| w | sauve et quitte |
| q | quitte sans sauver |
Ce qui donne:
|
Figure 67.
|
Une fois la table des paritions crée ou modifiée, il faut formater ces partitions avec la commande mkfs -t (type) /dev/partition ou mkfs.type /dev/partition .
Les différents types sont : swap; ext2; ext3; reiserfs; xfs; jfs; vfat.
Le montage s'effectue par la commande mount et le démontage par la commande umount . Par exemple:
 |
Figure 68.
|
 |
Figure 69.
|
Toutes les partions sont répertoriées dans le fichier /etc/fstab qui contient donc:
Les renseignements sur les différentes partitions
les partitions à monter automatiquement au démarrage
Chaque ligne de ce fichier contient six parties:
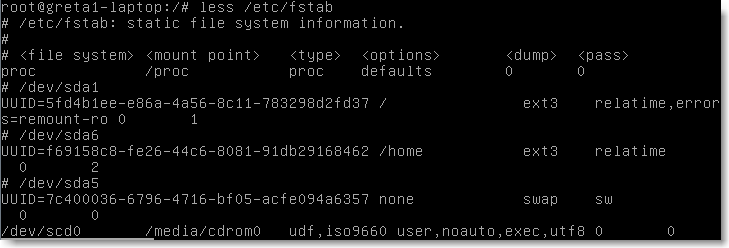 |
Figure 70.
|
le chemin du périphérique matériel dans /dev .
le point de montage
le type de système de fichiers.
les options de la commande mount .
le mot-clé dump qui active ou non (0 ou 1) la sauvegarde du disque avec la commande dump .
le mot-clé fsck qui permet d'activer la vérification du système de fichiers avec la commande fsck (valeurs: 0,1,2,3).
Sous linux, les différents types d'interface réseau sont répertoriés par un nom suivi d'un numero correspondant à l'ordre dans lequel le noyau va les détecter.
| Interface | Nom |
| ethernet | eth |
| token ring | tr |
| fibre optique | fddi |
| wifi | wlan |
| modem | ppp |
Il existe deux commandes qui permettent de configurer automatiquement les interfaces réseau lorsque la machine est située dans un environnement comportant un serveur dhcp. Ces deux commandes utilisent donc le même protocole dhcp et ne dépendent que de la distribution. Elles doivent être exécutées en root:
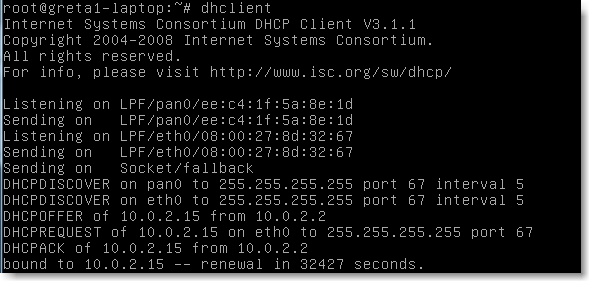 |
Figure 71.
|
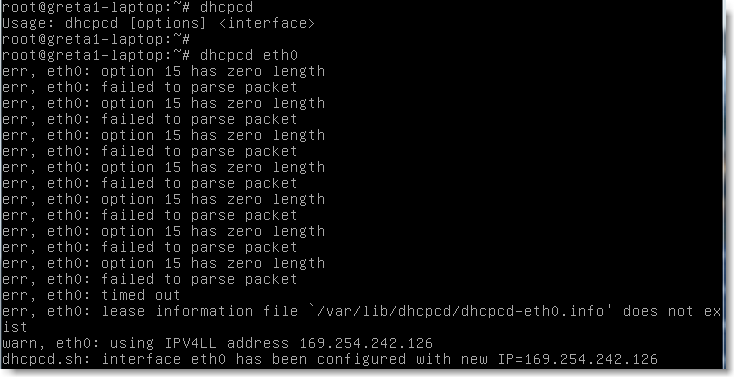 |
Figure 72.
|
On peut naturellement configurer manuellement une interface réseau avec la commande ifconfig . Sans argument, cette commande permet d'afficher l'état des interfaces réseau:
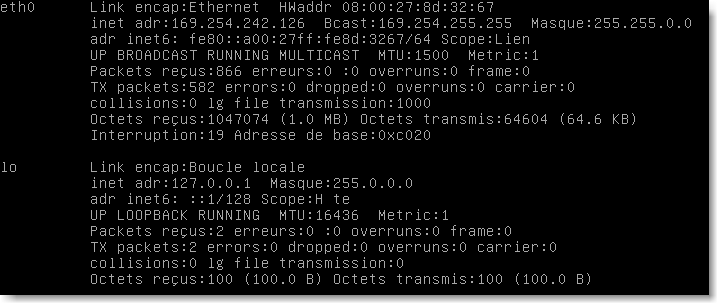 |
Figure 73.
|
La machine virtuelle ne présente ici qu'un interface réseau externe nommée eth0 et une interface interne (donc virtuelle) nommée lo (loopback).
La commande ifconfig permet donc également de configurer une interface manuellement:
 |
Figure 74.
|
On remarquera que l'adresse de broadcast est optionnelle, le système étant capable de la calculer lui-même.
Le fichier contenant la configuration réseau est:
 |
Figure 75.
|
Une autre méthode consiste à ajouter une ligne de configuration dans un fichier/etc/rcX.d/rc.local et pour finir il reste encore la configuration en mode graphique.
Contrairement aux systèmes de l'oncle Bill, linux configure séparément les routes de l'adresse ip d'une interface. On utilise la commande route pour atteindre un réseau distant. La commande propose alors dans certains cas des raccourcis.
Pour accéder à internet à partir d'un réseau privé, on utilise la route : passerelle par défaut .
Il n'y a besoin de spécifier les routes que lors d'un configuration manuelle du réseau.
 |
Figure 76.
|
pour ajouter une route, on utilise l'option add . Par exemple, pour indiquer qu'il faut utiliser l'interface eth0 pour joindre le réseau 172.10.x.x on saisit:
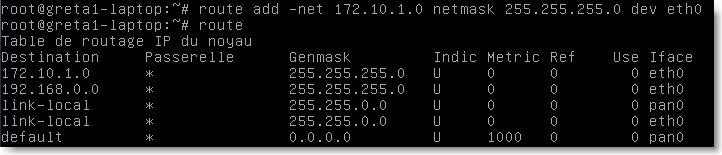 |
Figure 77.
|
Le mot-clé pour la passerelle par défaut est gw . Par exemple, on indique que la passerelle par défaut est à l'adresse 192.168.1.1 par la commande:
 |
Figure 78.
|
Le Domain Name System est configuré par le fichier /etc/resolv.conf :
 |
Figure 79.
|
Il y a deux informations dans ce fichier(même si, ici une seule apparaît):
nameserver indique l'adresse ip du serveur dns (il peut y en avoir plusieurs) .
domain qui spécifie le suffixe du domaine (ex.: mondomaine.com)
Pour tester la connectivité du réseau, on dispose également de :
ping
traceroute
par exemple:
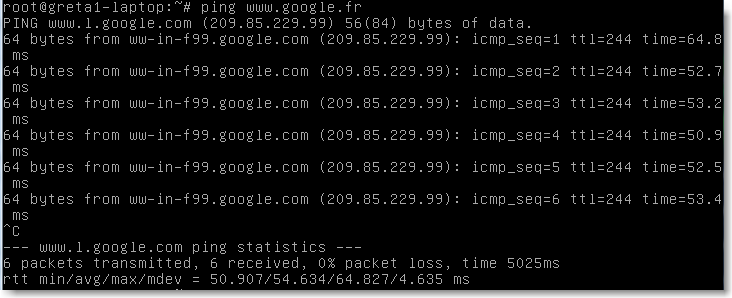 |
Figure 80.
|
Remarque: on interrompt la commande avec ctrl-c . On peut également spécifier le nombre de messages avec l'optio -c :
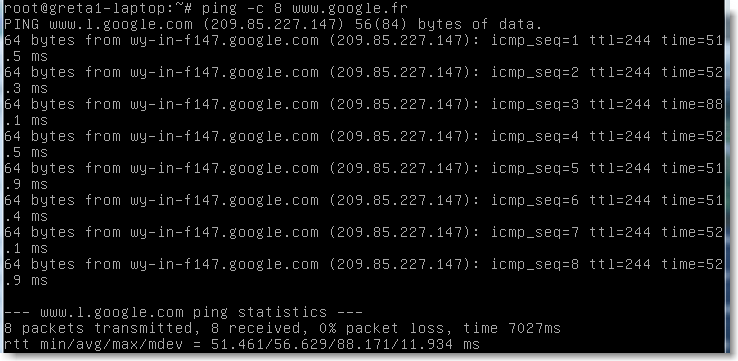 n n |
Figure 81.
|
La commande traceroute donne la liste des routeursparcourus entre la source et la destination. Pour chaque routeur, 3 paquets de test sont envoyés et le temps affiché. L'option -n permet de ne pas faire les traductions adresse/nom et augmente la vitesse de l'affichage.
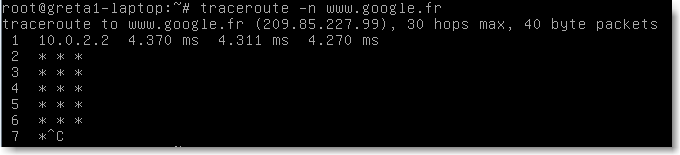 |
Figure 82.
|
L'installation des programmes se fait principalement de deux manières:
à partir de packages dont le format varie selon la distribution (.deb; .rpm principalement)
à partir des sources du programme
Les distributions à partir de red hat, mandriva utilisent rpm. Les distributions à partir de debian utilisent soit dpkg et apt-get. On remarquera que les paquets rpm de red hat et mandriva ne sont actuellement plus compatibles !
Les paquet .deb , utilisés par debian, ubuntu, knoppix sont, comme les rpm, des logiciels précompilés pour la distribution. Dés le début, les paquets deb ont étés prévus pour être récupérés par internet. La commande utilise pour cela le fichier /etc/apt/source.list qui contient une liste d'adresses de serveurs où se trouvent les programmes.
La syntaxe de la commande est : apt-get install package
la commande rapatrie le ou les fichiers puis dpkg -i installe le paquet. apt-get permet aussi de mettre à jour ou de désinstaller un programme.
On peut aussi rapatrier les sources d'un programme et en faire un paquet .deb avec la commande: dpkg-build paquet -r fakeroot -uc -b .
On peut, pour finir utiliser les programmes conçus en interface graphique !!!
Pour les distributions comme Gentoo ou pour les programmes dont on ne dispose que des sources, il faut procéder à une installation manuelle en trois points:
les sources étant installées et décompressées dans un répertoire, il faut les configurer(par un script ./configure).
les sources étant configurées, il faut compiler le programme avec la commande make .
puis il faut installer le programme compilé avec la commande make install .
par exemple (à partir du mode graphique):
récuper le dernier tarball d'amsn
le décompresser dans votre répertoire personnel (téléchargement)
configurer, compiler et installer l'application
 |
Figure 83.
|
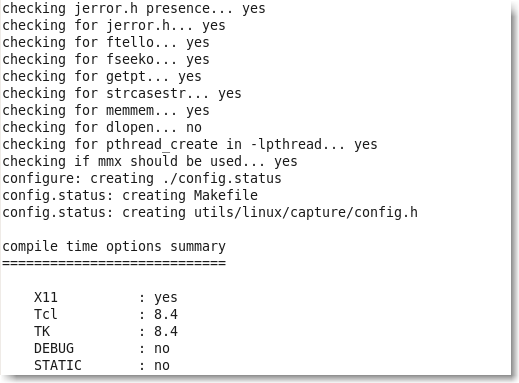 |
Figure 84.
|
 |
Figure 85.
|
 |
Figure 86.
|
 |
Figure 87.
|
 |
Figure 88.
|
Un script est un ensemble de commandes placées dans un fichier texte dans lequel chaque ligne correspond à une ligne de commande qui aurait pu être saisie dans un terminal. Le script est destiné à un interpréteur de commandes comme bash ou sh qui va le lire, l'analyser et l'exécuter.
C'est la première ligne qui détermine l'interpréteur à utiliser:
#!/bin/bash pour un script en bourne-shell
#!/bin/perl pour un script en perl
Par convention, un script peut comporter l'extension .sh, mais ce n'est bien sûr pas obligatoire. Les droits doivent êtres correctement choisis, notamment le script doit être executable.
Nous allons créer un script bash qui lors de son execution va afficher “bonjour à tous !” sur l'écran. Voilà le contenu:
#! /bin/bash
# debut du script
echo “Bonjour à tous !”
#fin du script
Remarque: si vous ajoutez le caractère & à la fin d'une commande, celle-ci est executée en tâche de fond.
Le fichier sera appelé monscript.sh.
Pour l'executer on utilise:
source monscript.sh (execute dans le shell d'origine)
. monscript.sh (execute dans le shell d'origine)
./monscript.sh (execute dans un shell secondaire)
bash monscript.sh (execute dans un shell secondaire)
Une fois executé, le script renvoie le code de retour de la dernière commande. Par convention, une valeur égale à 0 indique le bon déroulement du script et une autre valeur indique une erreur. On peut renvoyer cette valeur également par la commande exit 0 qui provoque alors l'arrêt du script. On retrouve dans un script les commandes suivantes:
mot-clé (if, case,...)
commande interne (echo, umask,...)
fonction définie par l'utilisateur
commande externe (qui appartient aux chemins de la variable PATH)
type vous renvoie le type de la commande:
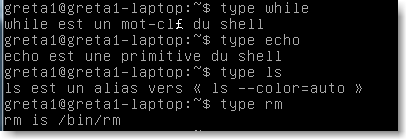 |
Figure 89.
|
un point virgule dans un script sépare deux instructions qui devraient être sur deux lignes différentes.
Deux commandes peuvent êtres executées en parralèle avec comme séparateur &
La deuxième commande peut être executée sur erreur de la première avec ||
La deuxième commande peut être executée sur réussite de la première avec &&
Le résultat d'une commande peut être utilisé comme paramètre d'une seconde commande avec la syntaxe: commande1 ‘commande2
On affiche donc à l'écran avec la commande echo qui peut renvoyer des caractères spéciaux par l'option -e (comme avec printf en langage C).
La commande read permet de lire une entrée clavier.
Il est également possible de créer des menus (commande select), d'effectuer de redirections, d'utliser des variables simples et des variables d'environnement, d'utiliser des paramètres, des strucures conditionnelles et de faire des calculs mathématiques à l'intérieur d'un script.
En conclusion , le scripting bash est un langage puissant qui peut faire l'objet d'une étude séparée en liaison avec de l'algorithmie.
Il existe de nombreux serveurs FTP sous linux. Nous installerons ici PUREFTPD qui est assez complet. Il permet notamment:
le réglage de la bande passante
le transfert entre deux serveurs FTP ( ou FXP)
le support des ratios
le chroot des répertoires
le choix des ports en téléchargement (mode passif)
l'authentification par ldap/mysql/postgresql/ssl.
Le File Transfert Protocol a été créé dés 1971 et est basé sur le modèle client/serveur. Il utilise par défaut les ports 20 (données) et 21 (commandes).
Son principale défaut est de ne crypter aucune données, pas même le couple login/password. Pour cette raison, certaines précautions sont à prendre:
Eviter d'implémenter un serveur FTP dans un réseau non commuté (avec des concentrateurs)
Eviter d'implémenter un serveur FTP dans un réseau comportant des services critiques (mails, DNS)
Faire en sorte que le compte root ne puisse pas se connecter au serveur FTP
Ne pas installer des données importantes ou confidentielles sauf si la sécurité a été renforcée par exemple par:
un cryptage SSL/TLS
le chrootage des utilisateurs dans leur répertoire (ce qui a pour effet de montrer à un utilisateur son répertoire comme étant le point le plus haut qu'il peut atteindre, comme si cela était la racine du disque)
l'utilisation d'utilisateurs virtuels
Un utilisateur virtuel ne peut se connecter que par le FTP . Tout autre type de connexion lui est interdit. Comme tout utilisateur doit posséder un UID/GID pour obtenir des droits, on attribue à l'utilisateur virtuel l'UID d'un utilisateur système existant (que l'on nomme souvent ftpuser ) qui ne possède pas de shell ni de mot de passe ou de l'utilisateur courant en changeant le mot de passe. On procède de même pour le GID.
On fixe alors la bande passante, les quotas et les horaires d'accés dans un profile qui peut être unique pour chaque utilisateur.
On commence par récpérer le dernier tarball:
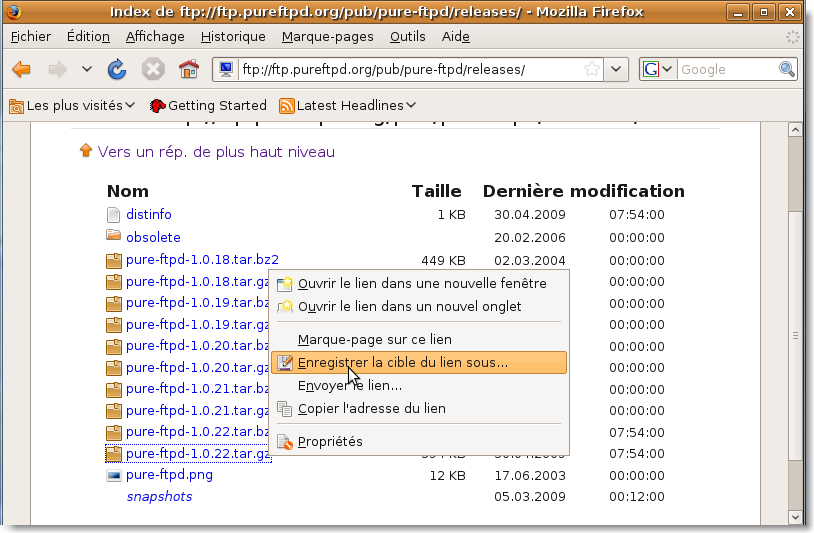 |
Figure 90.
|
Puis, dans un terminal, on décompresse l'archive:
 |
Figure 91.
|
et, dans le répertoire de pureftpd on configure compile et installe le logiciel:
 |
Figure 92.
|
Remarque: les options passées à la commande configure permettent d'obtenir dans l'ordre:
activation du support des utilisateurs virtuels
activations des liens symboliques pour les utilisateurs chrootés
activation de la commande ftpwho
activation des fichiers de log avancés
activation de la gestion de la bande passante
activation de la gestion des limites par utilisateur
désactivation du support inrtd pour gagner de la place
puis:
 |
Figure 93.
|
 |
Figure 94.
|
Et voilà l'installation terminée.
Commençons par créer le groupe et l'utilisateur :
 |
Figure 95.
|
L'utilisateur ftpuser ne pourra donc pas se connecter au système, son home directory et son shell étant invalides.
PureFTPd est ensuite démarré par:
 |
Figure 96.
|
où la signification des options est (dans l'ordre):
-c 5 pour limiter le nombre de connexions à 5
-C 1 pour limiter le nombre de connexions par IP à 1
-E pour désactiver les connexions anonymes
-O pour activer et spécifier le fichier de log ainsi que son type (clf-apache;stats;w3c)
Remarque: On peut utiliser la commande pure-ftpd sans indiquer le chemin complet si le chemin /usr/local/sbin est bien dans la variable d'environnement, ce qui peut être ajouté avec la commande export :
 |
Figure 97.
|
Arrêter le serveur PureFTPd :
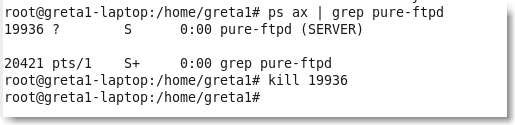 |
Figure 98.
|
Le premier nombre obtenu dans la réponse est le numéro de process PureFtpd. il faut le tuer(commande kill).
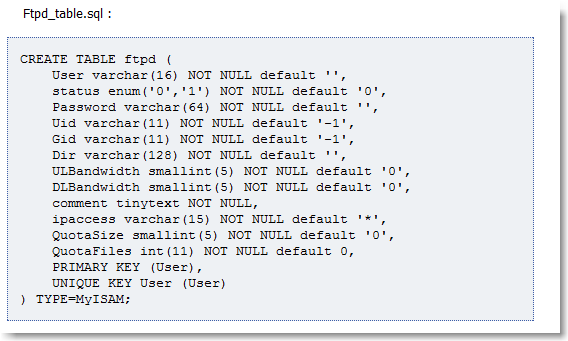
De façon analogue au fichier /etc/passwd le fichier /etc/pureftpd.passwd contient les utilisateurs et leurs paramètres (un utilisateur par ligne).
Ce fichier est alimenté par la commande pure-pw . Par exemple:
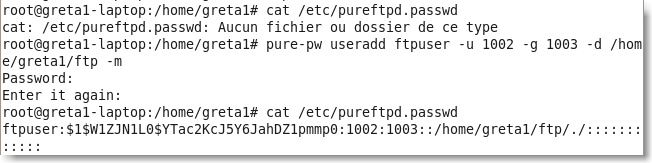 |
Figure 99.
|
Les différentes actions de la commande pure-pw sont:
| Option | Effet |
| useradd | ajout d'un utilisateur virtuel |
| usermod | modifier un utilisateur virtuel |
| userdel | supprimer un utilisateur virtuel |
| passwd | modifier le mot de passe d'un utilisateur virtuel |
| show | afficher le profil d'un utilisateur virtuel |
| list | lister tous les utilisateurs virtuels |
| mkdb | recréer la base de données PureFTPd (/etc/pureftpd.pdb) |
Les options de la commande pure-pw useradd sont:
| Option | Effet |
| -u | précise l'UID de l'utilisateur virtuel (en principe celui de ftpuser) |
| -g | précise le GID de l'utilisateur virtuel (en principe celui de ftpgroup) |
| -d | précise le répertoire personnel de l'utilisateur dans lequel il sera chrooté |
| -D | précise le répertoire personnel de l'utilisateur |
| -t | précise le débit maximum de l'utilisateur en download |
| -T | précise le débit maximum de l'utilisateur en upload |
| -y | recrée la base de données PureFTPd (/etc/pureftpd.pdb) |
| -z | précise les heures de connexion (-z 1400-1800 :entre 14H et 18H) |
| -Q | précise le ratio de l'utilisateur en download |
| -q | précise le ratio de l'utilisateur en upload |
autre exemple: :
 |
Figure 100.
|
 |
Figure 101.
|
Le nombre 12 est celui qui indique le maximum de connexions simultanées pour l'utilisateur virtuel.
L'option -m à la fin de la commande récrée automatiquement la base de donnée pureftpd.pdb et est donc équivalente à la commande pure-pw mkdb .
Les commandes pure-pw usermod et pure-pw passwd suivent la même syntaxe et nécessitent également de recréer la base de données (option -m).
Il est également possible de supprimer un utilisateur virtuel ou même de convertir un utilisateur système en utilisateur virtuel:
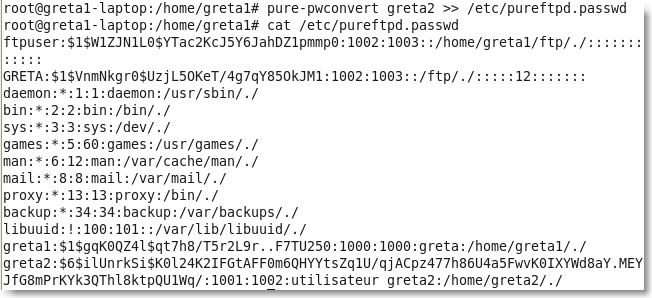 |
Figure 102.
|
 |
Figure 103.
|
Et pour voir les informations d'un utilisateur:
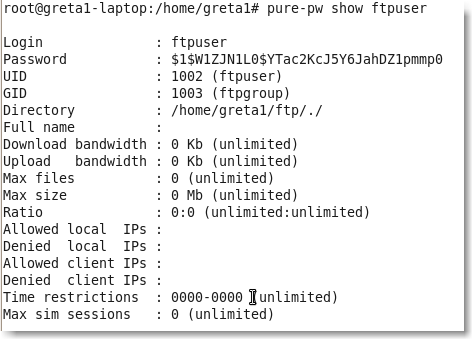 |
Figure 104.
|
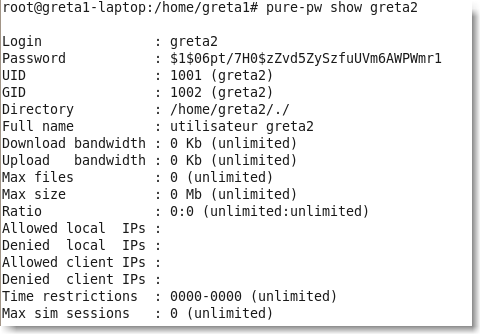 |
Figure 105.
|
Pour activer la gestion des utilisateurs virtuels par le serveur, il faut ajouter à la commande de démarrage du serveur l'option -l puredb:/path/to/puredb_file, ce qui dans notre exemple donne:
 |
Figure 106.
|
On peut lister à tout moment les utilisateurs connectés par la commande pure-ftpwho:
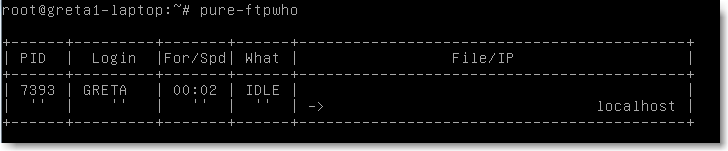 |
Figure 107.
|
Vous pouvez également , à tout moment, consulter le fichier de log:
 |
Figure 108.
|
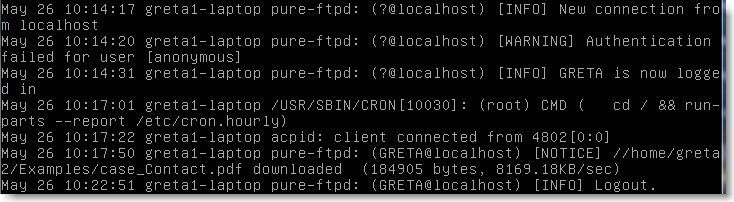
Il indique ici que le serveur a envoyé le fichier ”case Contact.pdf” à l'utilisateur GRETA.
L'examen des fichiers messages et syslog est également instructif:
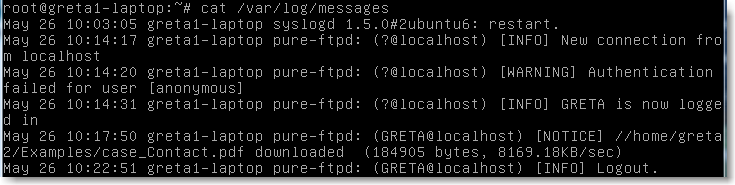 |
Figure 109.
|
|
Figure 110.
|
Il est également très intéressant d'installer le paquet awstats qui permet, par une interface de page web d'obtenir toutes les statistiques sur le serveur, mais nécessite l'installation du serveur http apache :
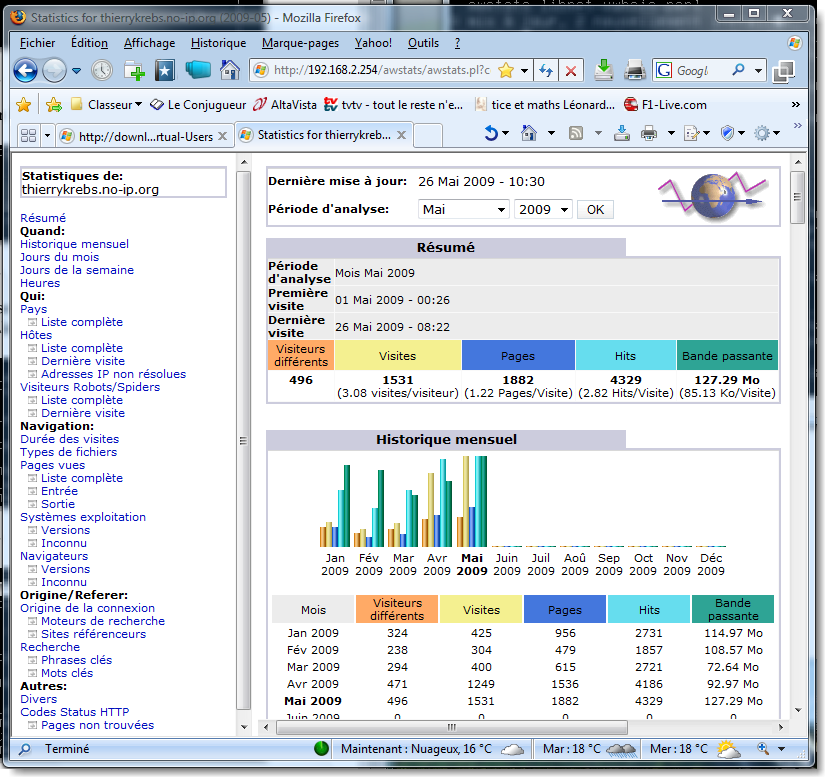 |
Figure 111.
|
Il est possible de configurer pureftpd pour qu'il utilise SSL pour crypter les noms d'utilisateurs et mots de passe. Pour des raisons de performances, on n'affectera pas le canal des données par eette encryption.
On commence par installer le paquet openssl et libssl-dev avec apt-get puis on crée la clé de sécurisation:
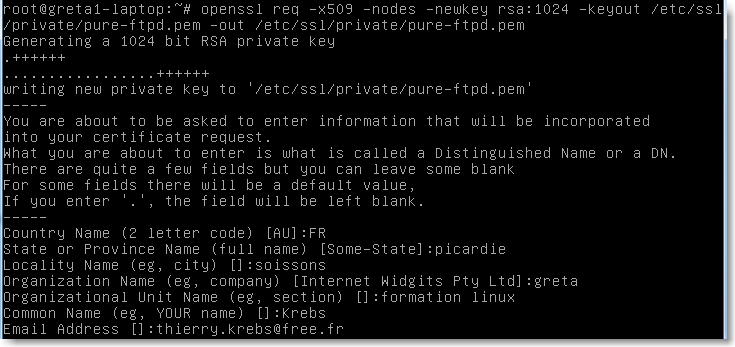 |
Figure 112.
|
Et on attribue les droits sur cette clé :
# chmod 600 /etc/ssl/private/*.pem
A savoir que le root aura un accès exclusif au fichier en question.
 |
Figure 113.
|
Il faut alors activer l'option TLS lors de la configuration des sources de pureftpd:
 |
Figure 114.
|
Puis il faut bien entendu recompiler et installer le programme.
Démarrage de Pure-ftpd en mode TLS
Tout d'abord, il faut savoir qu'il y a 3 modes différents pour utiliser le mode TLS avec Pure-ftpd :
–tls=0 : Désactivation du support SSL/TLS
–tls=1 : Connexions de client normaux ou sécurisé autorisé.
–tls=2 : Seul les clients sécurisés peuvent se connecter.
NOTE: l'argument –tls peut-être remplacer par -Y, dans cas on l'écrira ainsi -Y 2 .
Par exemple:
 |
Figure 115.
|
La connexion non cryptée n'est plus possible:
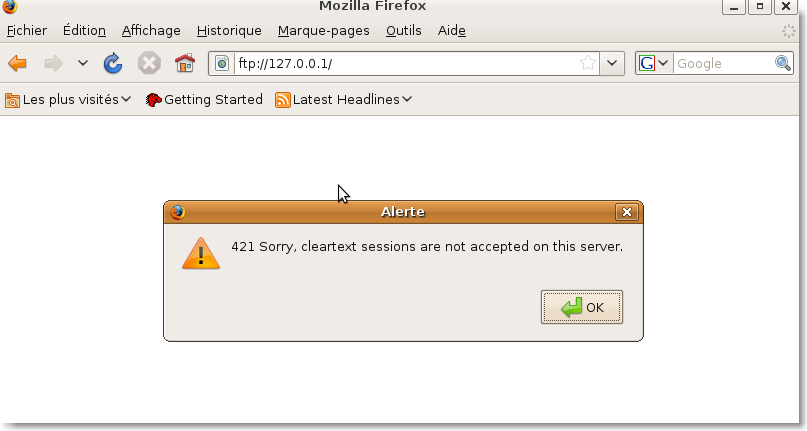 |
Figure 116.
|
Par contre avec filezilla (paquetage supplémentaire à installer) par exemple:
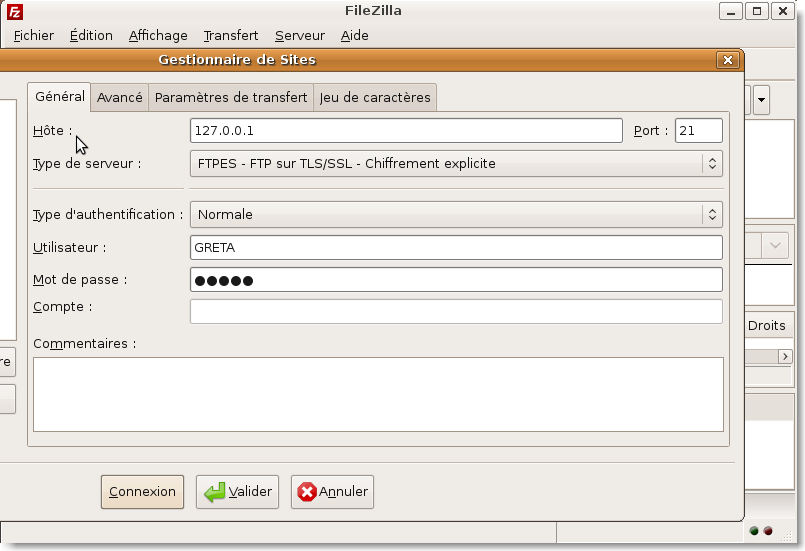 |
Figure 117.
|
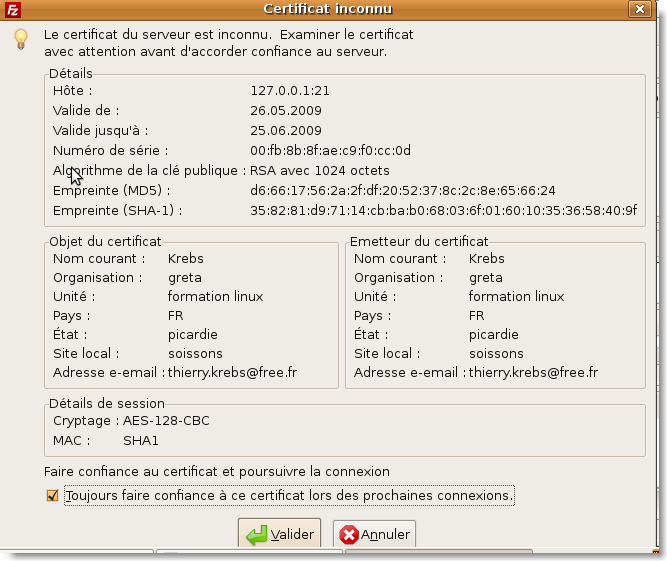 |
Figure 118.
|
L'utilisation d'une base de données telle que mysql simplifie l'administration d'un serveur ftp, notamment en présentant une interface de gestion par le web.
Pour commencer, il faut installer le paquet pure-ftpd-mysql et le paquet libmysqlclient15-dev. Ensuite il faut configurer les sources pour l'utilisation de mysql:
 |
Figure 119.
|
Puis à nouveau, executez make et make install.
Enfin on lance le serveur
|
Figure 120.
|
Il faut maintenant installer la base de données qui va accueillir les données de notre serveur. Pour cela installer mysql-client-5.0 et mysql-server-5.0, puis créer la base elle-même:
 |
Figure 121.
|
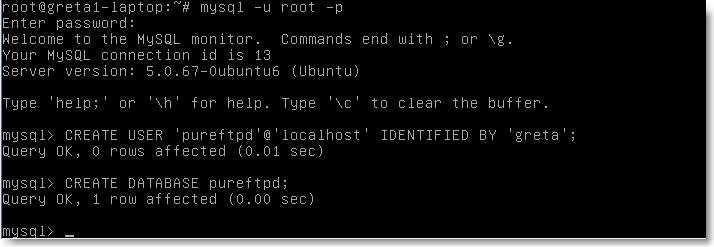 |
Figure 122.
|
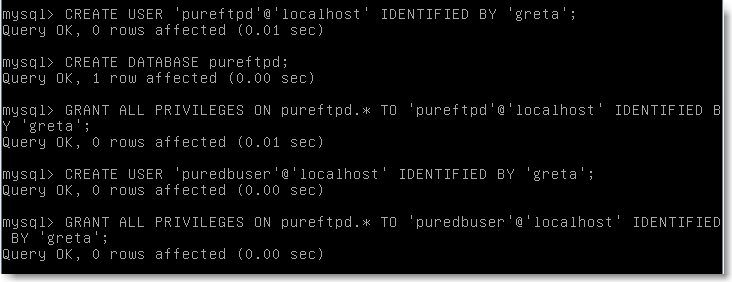 |
Figure 123.
|
Dans le répertoire /etc/pure-ftpd/db enregistrez la requête suivante dans le fichier texte:
|
Figure 124.
|
Puis executez la requête dans la base de données:
 |
Figure 125.
|
Pour tester , on peut ajouter un utilisateur :
 |
Figure 126.
|
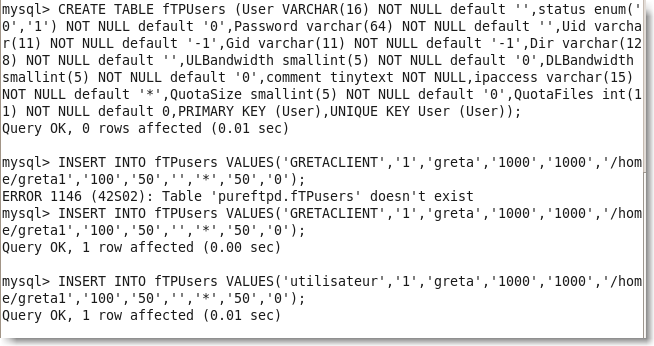 |
Figure 127.
|
Vous pouvez maintenant accéder au fichier de configuration /etc/pure-ftpd/db/mysql.conf :
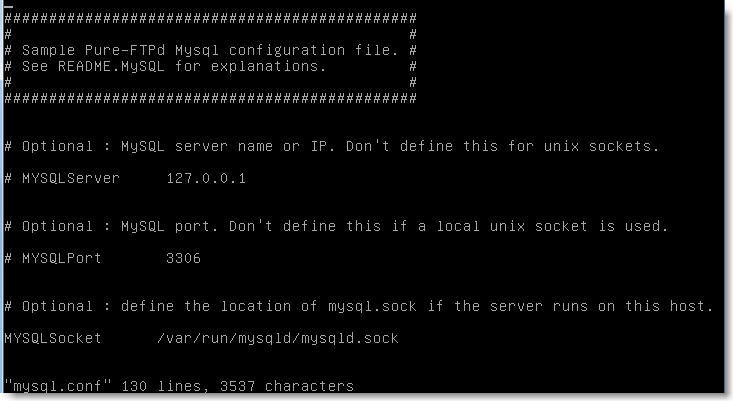 |
Figure 128.
|
Il est également possible d'utliser des interfaces comme pureadmin ou le module Pureftpd de Webmin (difficilement trouvable, et peu utilisé) pour gérer le trio mysql-apache-php (Lamp). Par contre webmin propose une interface simple de gestion de mysql :
Après l'installation du paquetage .deb de webmin, onse connecte par une interface web sécurisée sur le port 10 000 :
 |
Figure 129.
|
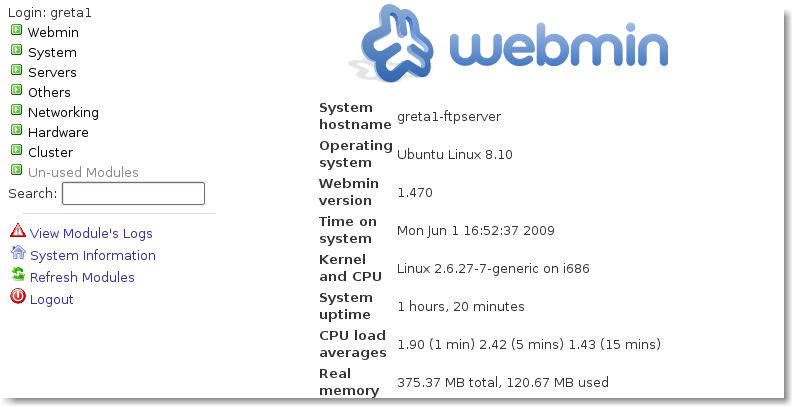 |
Figure 130.
|
 |
Figure 131.
|
 |
Figure 132.
|
 |
Figure 133.
|
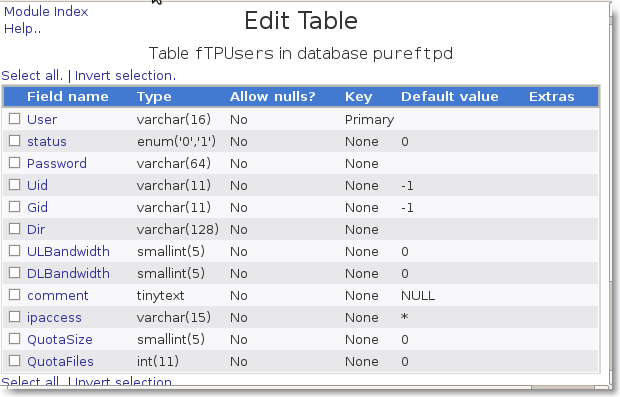 |
Figure 134.
|
Les extensions de webmin sont disponibles à l'adresse: http://www.webmin.com/third.html
Mais la meilleure interface graphique, à mon sens, pour gérer pureftpd est User manager for PureTTPd.
Il faut installer tous les paquets nécessaires:
sudo apt-get install php5 php5-cli apache2 apache2-doc mysql-server libapache2-mod-php5 php5-mysql
Vous pouvez exécuter les scripts PHP5 depuis une ligne de commande. Pour exécuter des scripts PHP5 depuis une ligne de commande, vous devez installer le paquet php5-cgi. Pour installer php5-cgi, vous pouvez saisir la commande suivante dans un terminal :
sudo apt-get install php5-cgi
Pour utiliser MySQL avec PHP5 vous devez installer le paquet php5-mysql. Pour installer php5-mysql, vous pouvez saisir la commande suivante dans un terminal :
sudo apt-get install php5-mysql
Réciproquement, pour utiliser PostgreSQL avec PHP5 vous devez installer le paquet php5-pgsql. Pour installer php5-pgsql, vous pouvez saisir la commande suivante dans un terminal :
sudo apt-get install php5-pgsql.
Il faut ensuite télécharger ftp_v2.1.tar.gz, puis décompresser l'archive et lancer le script install.php dans un navigateur web.
Après l'installation , on obtient:
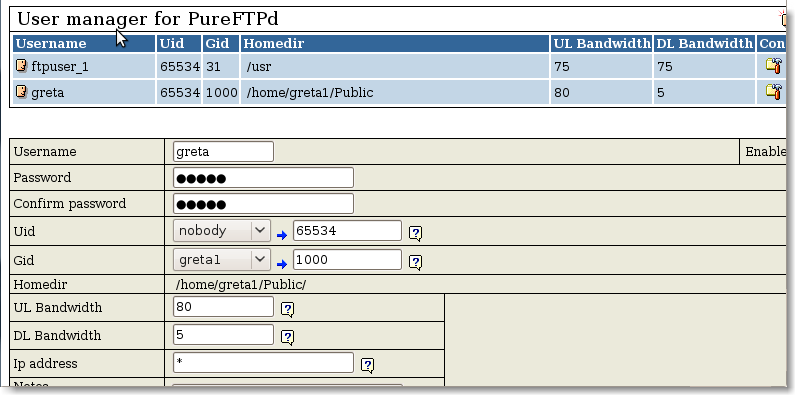 |
Figure 135.
|
avec le module de webmin:
 |
Figure 136.
|
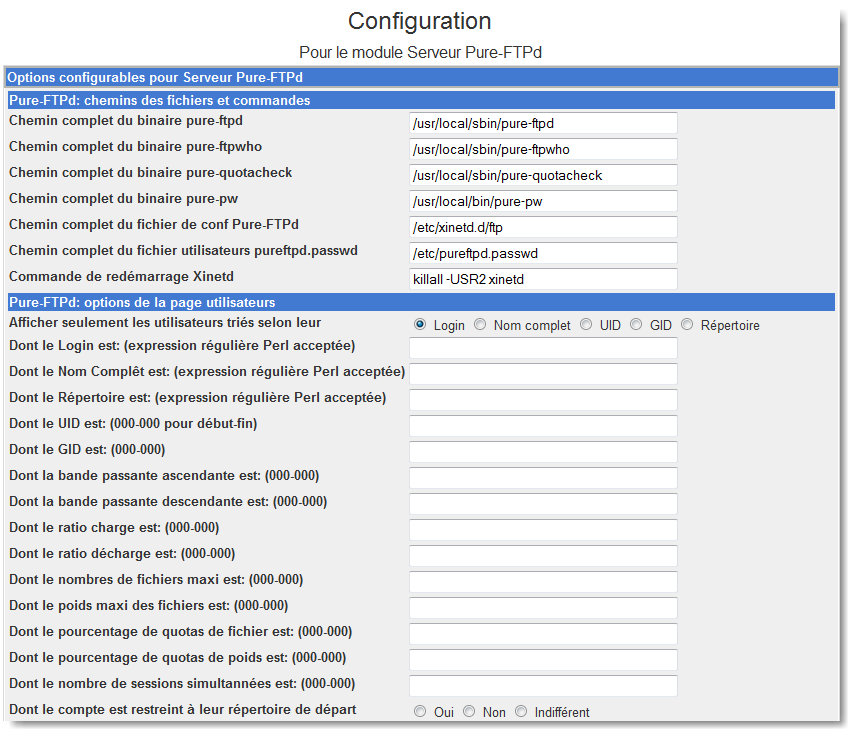 |
Figure 137.
|
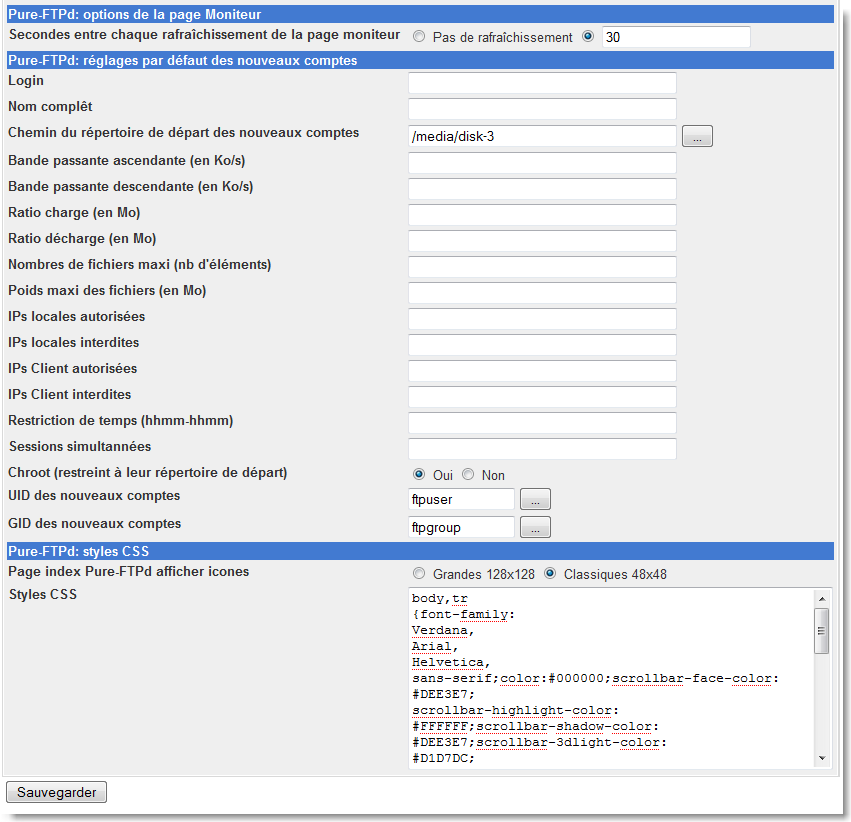 |
Figure 138.
|
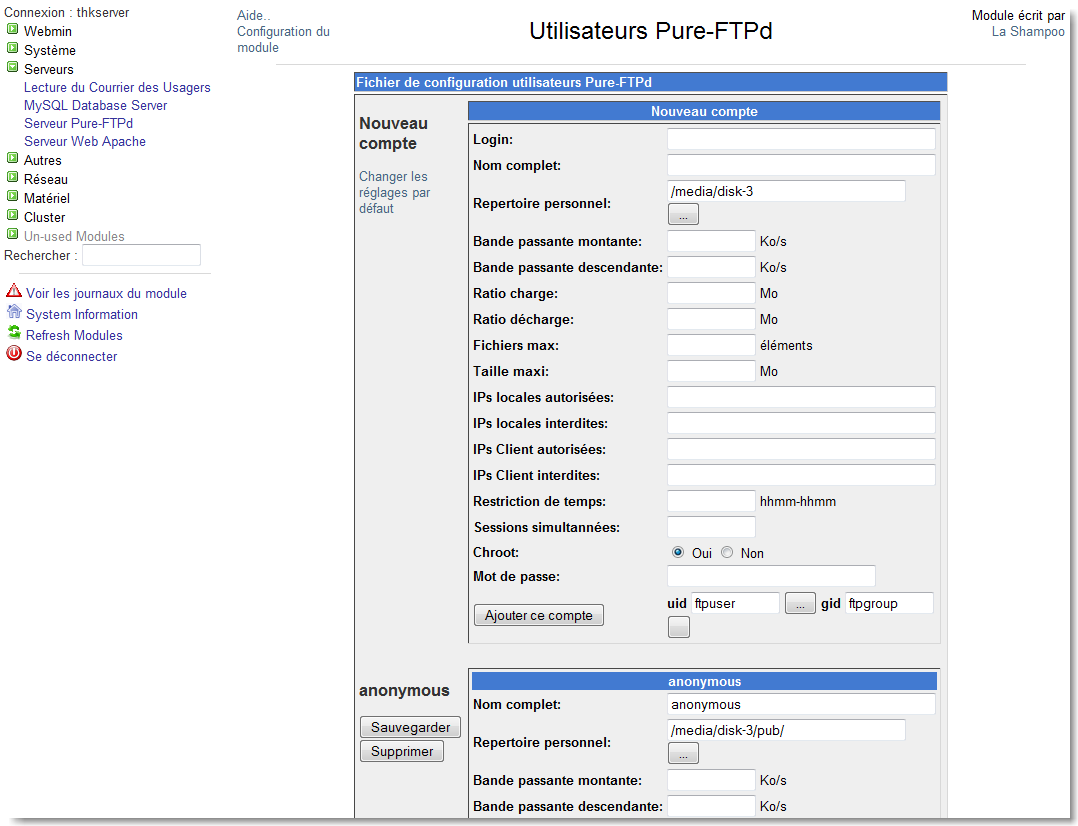 |
Figure 139.
|
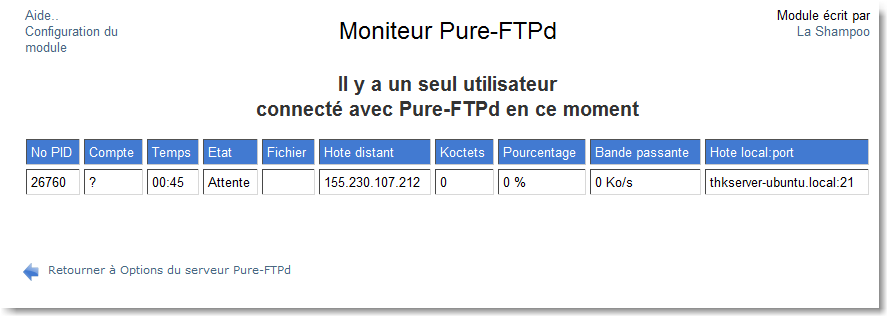 |
Figure 140.
|
Pour publier des pages web, il est nécessaire de les publier en utilisant un protocole universel qui est, à l'heure actuelle, le protocole Hyper Text Transfert Protocol. Ses principes de fonctionnement sont:
l'utilisation d'en-têtes décrivant le contenu de la page
l'utilisation du codage mime pour identifier les contenus
l'utilisation d'une relation type client-serveur
Le contenu des sites est obtenu en combinant l'utilisation d'un langage de scripts ou de programmation et d'une base de donnée, par exemple l'association PHP/MYSQL est très souvent employée.
Le serveur Apache représente environ 70 % des parts de marché. Sa principale qualité est l'évolutivité grâce à l'adjonction de modules (par exemple pour le support de php).
Nous allons donc installer apache.
En dehors de l'installation de paquets pré-compilés par l'intermédiaire de logiciels comme synaptic , il peut être interessant d'installer apache à partir des sources. Comme on peut s'en douter, l'avantage de cette méthode est de pouvoir choisir les options de compilation:
–préfix=<répertoire»> permet de définir le répertoire d'installation (/usr/apache2)
–bindir=<repertoire> permet de définir le répertoire des binaires utilisateurs (/usr/bin)
–sbindir=<repertoire> permet de définir le répertoire des binaires systèmes (/usr/sbin)
–enable-ssl active le support pour SSL
–with-ssl=<repertoire> indique le répertoire contenant les sources d'OpenSSL
–vhost-alias active le module pour les hôtes virtuels
Il y a actuellement plusieurs fichiers de configuration. Bien entendu httpd.conf qui est le premier de ces fichiers auquel on a ajouté des fichiers spécifiques pour, par exemple, gérer un hôte virtuel. Tous ces fichiers peuvent être intégrés à httpd.conf.
Un serveur http apache possède principalement deux modes de fonctionnement:
avec le demon inetd qui gére les connexions entrantes et sortantes mais demande beaucoup de ressources
en mode standalone dans lequel un serveur père écoute les interfaces réseaux et un serveur fils traite les requêtes des clients (c'est le plus utilisé).
Quand on a choisi le mode du serveur, il faut configurer l'environnement du serveur, c'està dire principalement:
les directives du serveur (répertoires,groupe d'utilisation...)
les directives de connexion (timeout,keepalive,maxclients,...)
Ouvrez le fichier httpd.conf:
Directives de configuration dans httpd.conf
Remarque: Il est également possible d'utiliser webmin.
Tout d'abord, une chose bien utile si vous ne souhaitez pas utiliser le répertoire de base de Apache pour vos documents web. Par défaut, le sous-répertoire qui contient les pages web se nomme htdocs, si vous souhaitez modifier cela, repérez le paramètre <DocumentRoot> puis modifier comme ceci :
DocumentRoot "e:/projet/www"
On aura pris soit de créer le sous-répertoire www dans e:/projet avant même d'avoir fait la modification dans le fichier de configuration, sinon cela aurait pour effet de générer une erreur lors du lancement d'Apache.
Si pour une raison ou pour un autre, on souhaite modifier l'adresse e-mail de l'administrateur du serveur, on repère le paramètre ServerAdmin puis on lui indique en valeur une adresse e-mail (de préférence valide).
ServerAdmin toto@nomdedomaine.com
Si l'on souhaite indiquer les fichiers qui seront traités comme des fichiers de base du serveur web, c'est-à-dire la page par défaut d'un répertoire web, nous pouvons modifier pour cela le paramètre DirectoryIndex.
DirectoryIndex index.htm index.html index.php index.php5
Ici, toutes les pages qui se nomment index.html, index.html, index.php ou index.php5 seront prises en compte par le serveur web comme page par défaut d'un site web.
Pour faire en sorte que le visiteur est un minimum d'information concernant votre serveur lorsque une page d'erreur type 404 s'affiche, nous pouvons modifier la valeur du paramètre ServerTokens.
ServerTokens Prod
En donnant la valeur Prod cela permet de ne fournir que le nom du serveur, soit dans le cas présent Apache, il n'y aura aucune information concernant la version utilisée ni d'autres informations qui pourraient renseigner une personne mal intentionnée.
Par ailleurs, je veille à fournir une adresse e-mail qui pourrait permettre au visiteur de m'informer d'un éventuel problème sur le serveur. Pour ce faire je modifie la valeur du paramètre Server Signature.
Comme ceci :
ServerSignature Email
Ce qui au final lorsqu'un message d'erreur est affiché permet à tout visiteur de pouvoir prévenir l'administrateur du serveur.
Une option qui est très utile est l'utilisation du module status, un module est une fonction qui permet d'ajouter des fonctions à votre serveur web.
Le module status permet dans le cas présent d'obtenir des informations en quasi temps réel sur l'état du serveur.
Pour ce faire dans le fichier de configuration, je vais rechercher la ligne suivante :
# LoadModule status_module modules/mod_status.so
Dans le cas présent, la ligne est actuellement en commentaire puisque ayant un # en son début de ligne.
Donc, on décommente tout d'abord la ligne :
LoadModule status_module modules/mod_status.so
Puis l'on recherche les quelques lignes ci-dessous (lignes qui dans leur version d'origine sont là aussi commentés #)
<Location/server-status>
SetHandler server-status
Order deny,allow
Deny from all
Allow from 127.0.0.1
</Location>
Ces quelques lignes permettent de rendre ou non disponible l'état du serveur. Le Deny from all permet tout d'abord interdit l'accès à tout le monde puis avec l'option Allow from 127.0.0.1 de l'autoriser uniquement à 127.0.0.1 (la consultation sera donc possible que depuis le serveur et non depuis une machine dans le réseau local par exemple).
Une fois la modification, on enregistre le fichier de configuration puis l'on ouvre son navigateur favori (Firefox par exemple).
Dans la barre d'adresse : http://localhost/server-status
Ceci ayant un résultat comparable à cela :
 |
Figure 141.
|
Voilà donc un aperçu de la configuration d'un serveur web Apache.
Il est également possible d'utiliser Kochizz interface graphique:
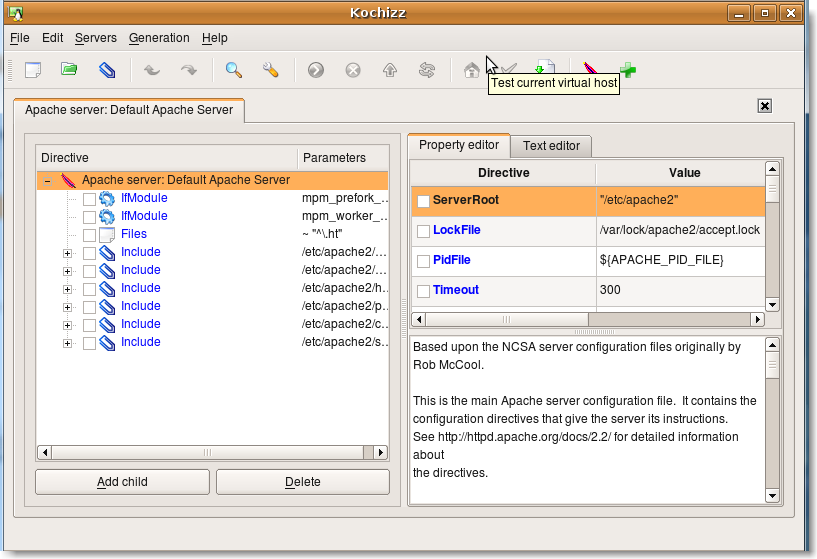 |
Figure 142.
|
Le système Dynamic Name Server , ou serveur dynamique de noms, permet de faire correspondre les adresses IP avec les noms des hôtes sur des réseaux distants.
Ce processus s'appuie sur une relation du type Client/Serveur où le client, aussi nommé resolver effectue une requête auprès d'un serveur de noms. Par exemple quand l'utilisateur entre dans la barre d'adresse de son navigateur : http://www.google.fr , ce dernier envoie une requête au serveur de domaine du fournisseur d'accès qui tente alors d'en déterminer l'adresse IP. Si le fournisseur d'accès n'est pas l'autorité pour le domaine de l'adresse entrée, il transmet la requête au domaine autorité de façon à obtenir la bonne réponse.
Chaque serveur de domaine doit donc posséder toutes les informations de la zone qu'il contrôle, mais aussi les informations de base sur les autres zones (il doit savoir où chercher l'information qu'il ne détient pas). Avant d'être résolue, une adresse peut donc transiter par plusieurs serveurs de domaines.
On appelle alors Fully Qualified Domain Name le nom d'hôte accompagné du nom de son domaine d'appartenance: www.google.fr est le nom complet de l'hôte www appartenant au domaine google.fr .
Pour demander des informations au serveur de nom, l'hôte client se connecte en général sur le port 53. Le serveur de nom essaye alors de résoudre le FDQN à partir de ses propres informations et des données mises en cache lors d'une demande antérieure. S'il n'a pas la solution, il envoie alors la demande à des serveurs de noms root afin de retrouver l'adresse d'un serveur de noms faisant autorité pour le FDQN en question.
Mis à part le nom de domaine, chaque section est appelée zone et définit un espace de nom spécifique. Un FDQN inclus donc au moins un sous-domaine, mais peut en comprendre beaucoup plus, en fonction de l'organisation du domaine.
Chaque zone est définie par son fichier de zone stocké sur les serveurs de noms primaires (master) qui font autorité sur les serveurs de noms secondaires (slave) qui reçoivent donc leur fichier de zone de ces master .
Un serveur de noms peut êtres à la fois master sur une zone et être slave sur une autre.
Enfin pour compléter la description, il existe des serveurs fonctionnant en caching-only (qui n'ont aucune autorité et ne servent qu'à accélérer le temps de réponse) et des serveurs fonctionnant en forwarding (qui ne font que transmettre la demande à une liste spécifique de serveurs de noms).
Sous linux, le paquet Berkeley Internet Name Domaine (BIND 9), contientle service /usr/bin/named qui est le serveur de noms de référence. Celui-ci est configuré par le fichier /etc/named.conf et stocke tous les fichiers de zone et de cache dans /var/named/ .
On peut maintenant récupérer le tarball de bind9 et l'installer:
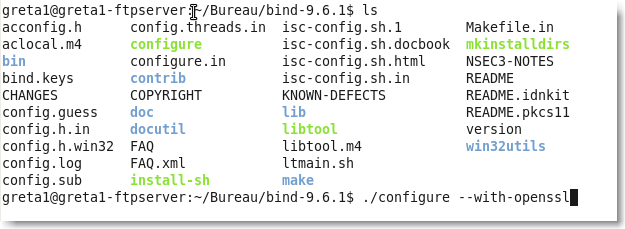 |
Figure 143.
|
l'option –with-openssl ajoute le support de DNSSEC qui sécurise le transfert des données entre master et slave. D'autre options peuvent être utiles, comme –enable-thread pour le support du multithreading ou encore –with-kame pour ajouter le support de l'IPv6 si celui-ci n'est pas pris en charge par le système.
Essayez:
 |
Figure 144.
|
On termine l'installation par make et make install en root. Il faut ensuite configurer en éditant /etc/named.conf qui est composé d'une suite de déclarations utilisant des options entre accolades qui définissent les caractéristiques du serveur:
les listes de contrôle d'accés dont le but est de définir des groupes d'hôtes qui pourront ensuite être rappelés juste par leur nom de groupe. voir:
 |
Figure 145.
|
les inclusions
les options
les déclarations de zone
Il faut ensuite instruire les fichiers de zone.